
股票配资是一种融资方式,允许投资者使用借入资金购买股票。配资公司会根据投资者的信用状况和投资标的提供一定比例的资金,通常为1:1至1:5。例如,如果投资者有10万元资金,并获得1:3的配资,则可以购买价值40万元的股票。
亚马逊目前正在进行全球最大的 AI 集群建设之一,部署了大量 Hopper 和 Blackwell GPU。除了对基于 Nvidia 的集群投入大量资本支出外,AWS 还向 Trainium2 AI 集群投入了数十亿美元的资本支出。AWS 目前正在为 Anthropic 部署一个名为“Rainier 项目”的包含 40 万个 Trainium2 芯片的集群。近一年来,我们行业领先的加速器模型已经掌握了单位数量、成本、规格以及与亚马逊与 Marvell 等公司合作的庞大规模相关的许多其他细节。
到目前为止,由于硬件规格较弱和软件集成度较差,亚马逊基于 Trainium1 和 Inferentia2 的实例在 GenAI 前沿模型训练或推理方面尚无竞争力。随着 Trainium2 的发布,亚马逊进行了重大的路线调整,并最终在芯片、系统和软件编译器/框架级别上提供具有竞争力的定制硅片进行训练和推理。
需要明确的是,由于其内部模型(如 Titan 和 Olympus)失败,亚马逊仍处于危机状态。此外,虽然他们已经稳固地在定制 AI 芯片竞赛中位居第二,仅次于谷歌,但他们仍然严重依赖 Nvidia 的产能。亚马逊的 Trainium2 并非经过验证的“训练”芯片,大部分容量将用于 LLM 推理。亚马逊对 Anthropic 的新 40 亿美元投资实际上将回到 Project Rainier 400k Trainium2 集群中,而且目前还没有其他主要客户。
AWS Trainium1 / Inferentia2 GenAI 弱点
2022 年,AWS 发布了 Trainium1 和 Inferentia2 芯片。Trainium1 芯片和 Inferentia2 芯片几乎相同,只是 Inferentia2 芯片只有两个 Neuronlink-v2 互连端口,而 Trainium1 有四个端口。
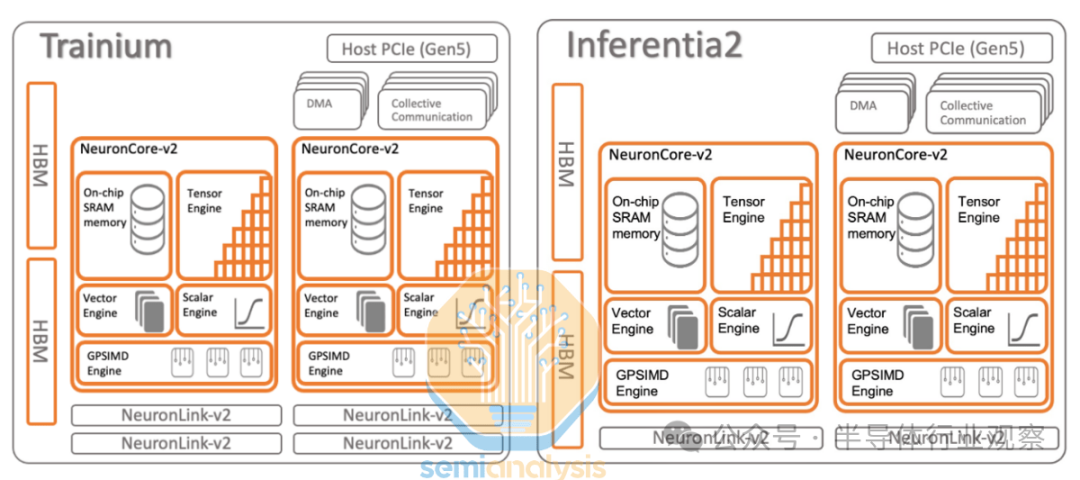
由于缺乏竞争力的纵向和横向扩展网络,Trainium1/Inferentia2 在 GenAI 训练方面表现不佳,许多软件错误也影响了客户的工作负载。因此,Trainium1/Inferentia2 被用于训练非复杂的非 GenAI 内部 Amazon 工作负载(例如信用卡欺诈检测 AI 模型)以及 Anthropic 和 Amazon 内部工作负载的推理。
讽刺的是,Trainium1 更适合 GenAI 推理而不是训练。在内部,亚马逊也一直在使用 Inferentia2 进行推理,例如在 2024 年 Prime Day,超过 80,000 个 Inferentia2/Trainium1 芯片被用于为亚马逊的基于 ML 的助手提供支持,帮助 Amazon.com Prime 会员。
AWS Trainium2 规格概述
随着 Trainium2 的出现,这一切都将发生改变,因为 AWS 现在坚定地瞄准复杂的 GenAI LLM 推理和训练工作负载,使用约 500W 的芯片,每个芯片具有 650 TFLOP/s 的密集 BF16 性能和 96GByte 的 HBM3e 内存容量。
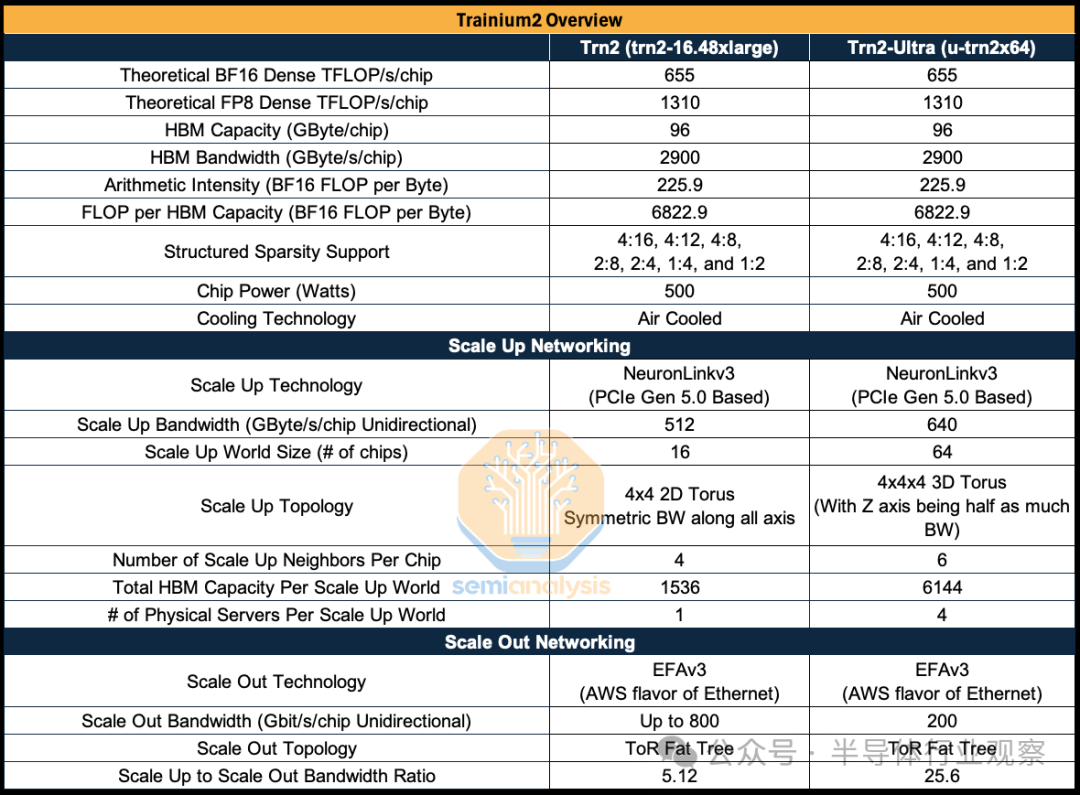
Trainium2 的另一个重要进步是其扩展网络。Nvidia 的扩展网络称为 NVLink,对于 H100,其每 GPU 的运行速度为 400Gbyte/s,而 InfiniBand 扩展网络的运行速度为 50Gbyte/s;Google TPU 的扩展网络称为 ICI,而 AWS 的扩展网络称为 NeuronLink。所有具有扩展网络的 AI 集群部署仍然使用后端扩展网络。扩展网络提供的高带宽域用于实现需要高带宽和低延迟的并行方案,例如张量并行,而扩展网络的低带宽域用于其他形式的并行,例如对延迟相对不太敏感的数据并行。Nvidia 通过其 GB200 NVL72 从 8-GPU NVLink 域转变为 72-GPU NVLink 域,这是将大型模型推理成本降低约 14 倍的最重要驱动因素之一,因为它可以实现多种多样的并行方案,而这在小型扩展网络域中是不可能实现的。
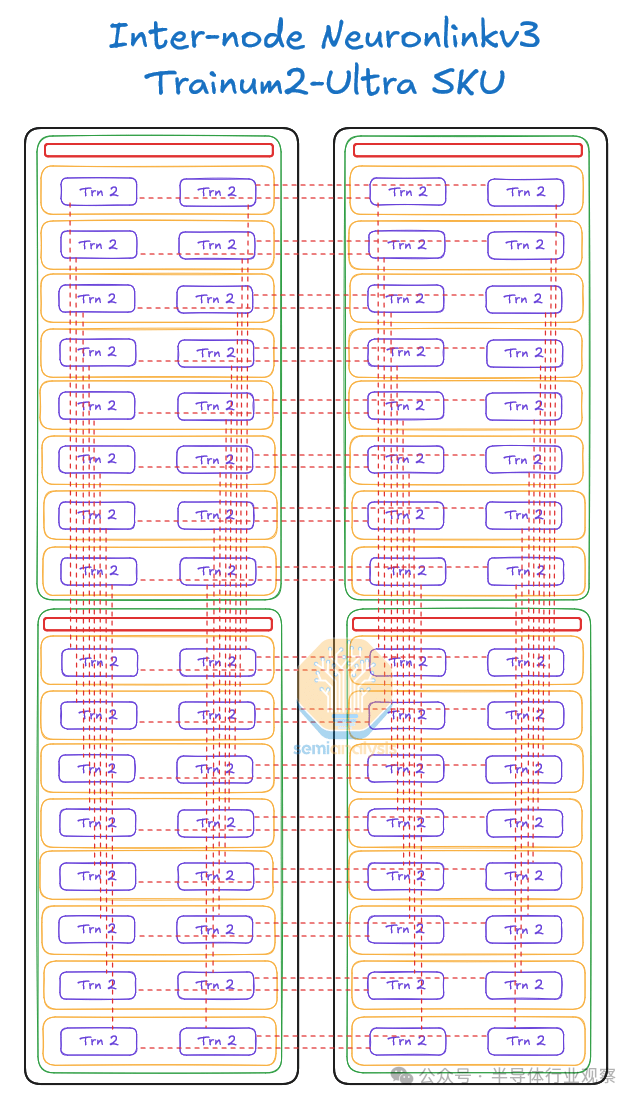
Trainium2 有两种 SKU,第一种是将每台服务器单元的 16 个 Trainium2 芯片连接在一起,形成一个 4×4 二维环面的单一扩展世界大小,而第二种是将每台服务器单元的 64 个 Trainium2 芯片(跨两个机架)连接在一起,形成一个 4x4x4 三维环面的单一扩展世界大小,称为 Trainium2-ultra。与仅具有 4×4 二维环面的 Trainium1 相比,Trainium2-ultra 现在提供了额外的连接维度。这个额外的维度允许在整个扩展域中进行张量并行和激活分片。
Trainium2-ultra 将成为 GenAI 前沿模型训练和推理的主要 SKU,用于亚马逊内部工作负载和 Anthropic 的工作负载。我们将在本文后面深入探讨 NeuronLink 扩展网络。
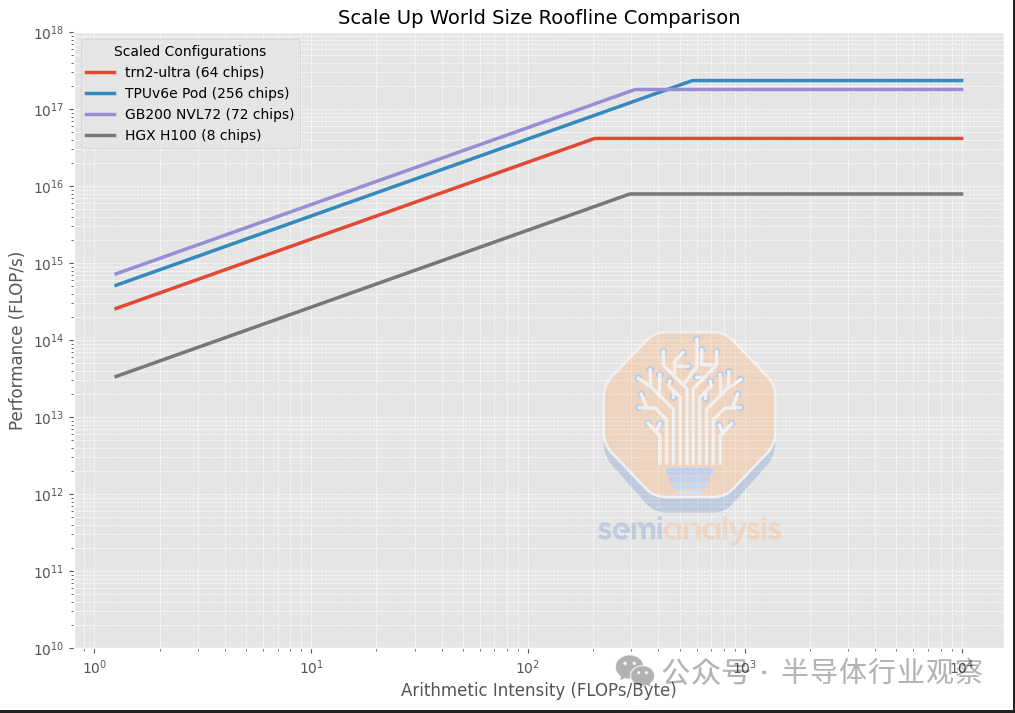
Trainium2 与 TPUv6e/GB200/H100 的比较
Trainium2 的扩展拓扑是 16 芯片 SKU/64 芯片 SKU 的 2D/3D 环面,这意味着 Trainium2 的扩展网络更接近于 TPU 类拓扑(除了 Trainium2 的世界大小要小得多),而不是 Nvidia NVLink 拓扑。关键区别在于 Trainium 和 TPU 具有点对点连接,而 NVLink 具有交换机并支持所有到所有连接。
Trainium2 与其他加速器的主要区别在于,其算术强度低得多,为每字节 225.9 BF16 FLOP,而 TPUv6e/GB200/H100 的目标是每字节 300 到 560 BF16 FLOP。算术强度是通过将 FLOP/s 除以 HBM 带宽(以字节/秒为单位)计算得出的,它表示计算吞吐量与内存带宽的比率。分析很重要,因为许多应用程序(例如推理)通常受到内存带宽的瓶颈限制,导致计算 FLOPS 未得到充分利用,因此不同的算术强度可能表明加速器更适合特定任务或技术——稍后将详细介绍这一点。
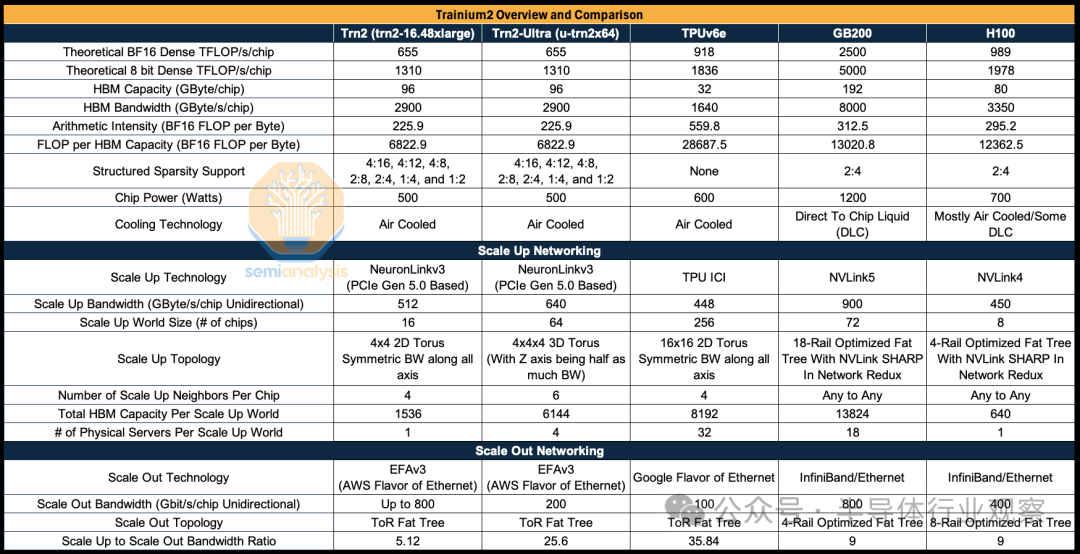
设计具有较低算术强度的 Trainium2 可能是正确的选择,因为由于 ML 研究的进步,模型的算术强度增长较慢。突出的例子包括非常流行的混合专家 (MoE:Mixture of Experts),它使用分组 GEMM。在分组 GEMM 中,每个 token 最多只会被路由到几个专家,因此加载权重所需的内存量与密集前馈网络 (FFN:feedforward networks) 相比要大得多,在密集前馈网络中,每个“看到”的 token 都会对每个权重进行计算。
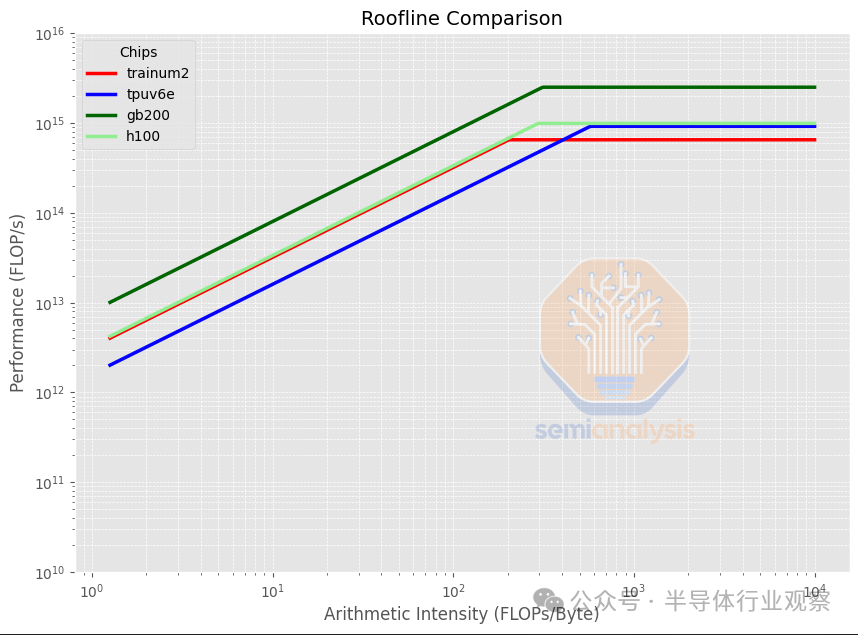
在按扩展域中的芯片数量进行标准化后,我们可以看到 Trainium2 仍然具有较低的算术强度,但是每个扩展的世界规模(Trainium2-Ultra 的情况为 64 个芯片)的聚合峰值 FLOP/s 都低得多,这是因为 Trainium2 的世界规模小于世界规模为 256 个芯片的 TPUv6e。
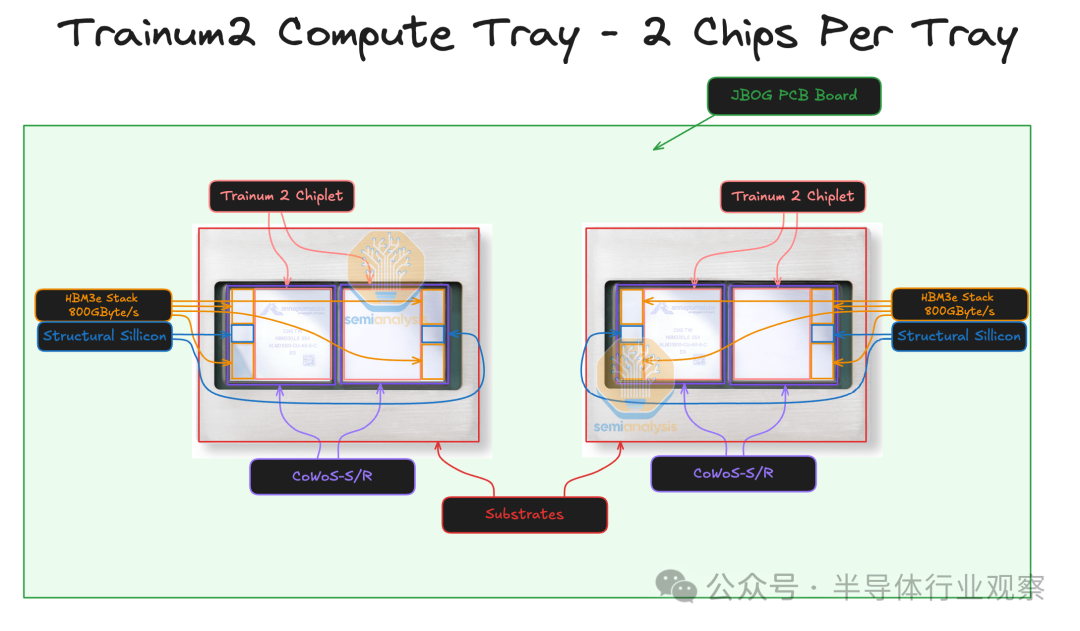
AWS Trainium2 的封装
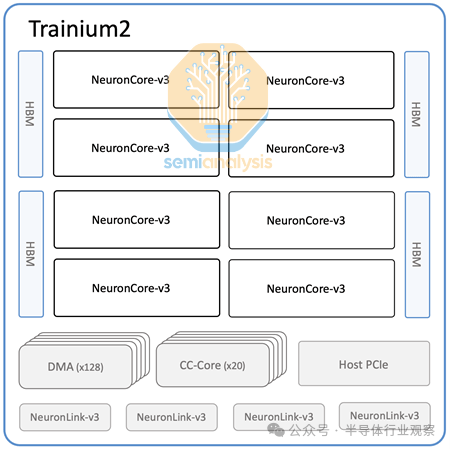
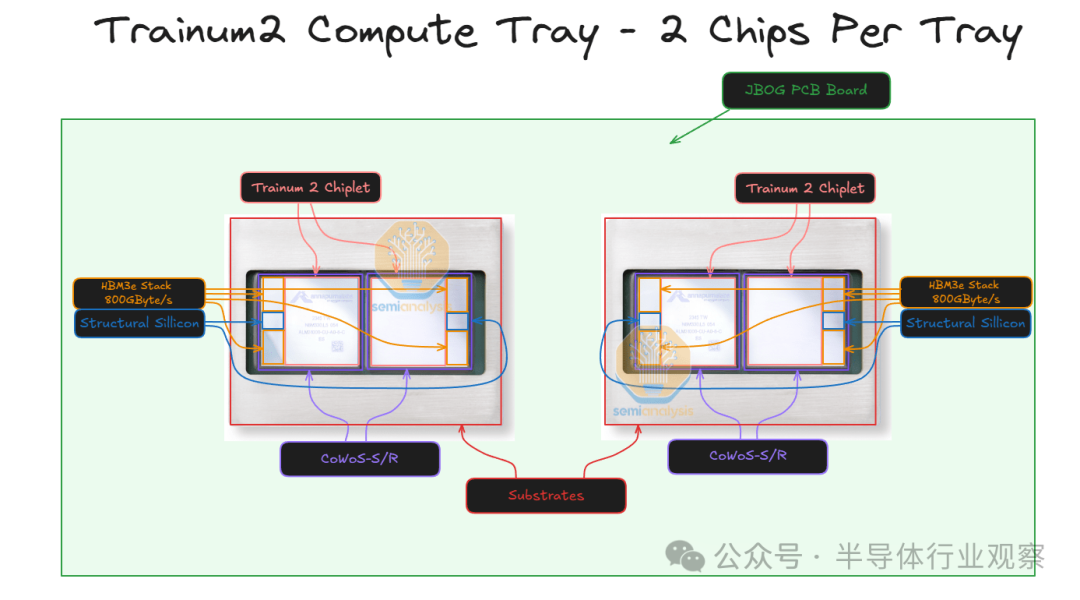
每个 Trainium2 芯片由两个计算芯片组和四个 HBM3e 内存堆栈组成。每个计算芯片组通过 CoWoS-S / R 封装与其两个直接的 HBM3e 堆栈通信,芯片的两半通过 ABF 基板相互连接。当计算芯片组尝试访问非直接相邻的 HBM 堆栈的内存时,性能会略有下降,并且可能需要 NUMA 感知编程才能实现与 MI300X 芯片组类似的峰值性能。还有两个无源结构硅片。
AWS Trainium2 微架构
和 Trainium1 和 Google TPU 一样,Trainium2 由少量大型 NeuronCore 组成。这与 GPU 形成对比,后者使用大量较小的张量核心。大型核心通常更适合 GenAI 工作负载,因为它们的控制开销较少。在 H100 SXM 上,有 528 个张量核心,在 GB200 上,有大约 640 个张量核心。每个 NeuronCore 中有四个引擎:
张量引擎
矢量引擎
标量引擎
GPSIMD
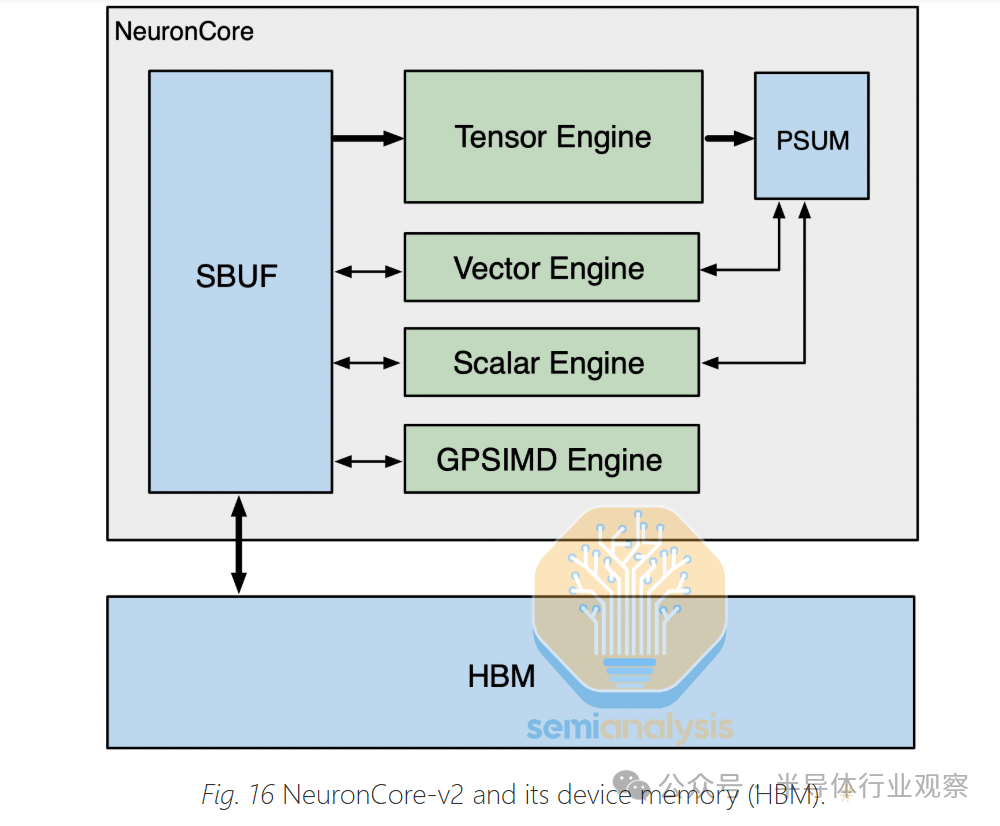
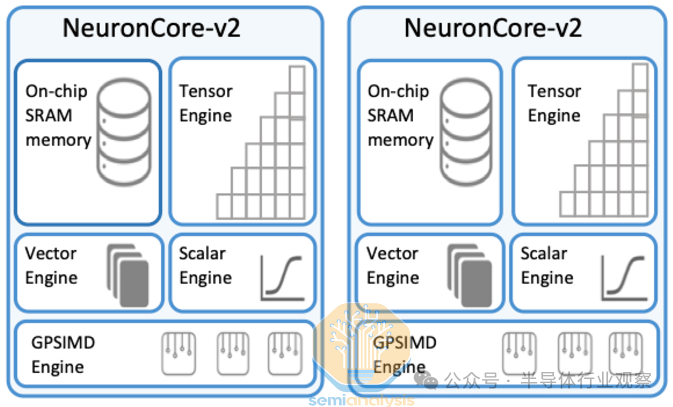
首先是张量引擎,它是一个 128×128 脉动阵列,它从名为“SBUF”的 SRAM 缓冲区收集输入,并将其结果输出到名为“PSUM”的部分和 SRAM 缓冲区中。张量引擎可以循环矩阵乘法 (matmul) 的 K 维,并将每个结果的部分和相加以获得完整结果。张量引擎/脉动阵列是现代 LLM 工作负载的 80% 以上的功率和 FLOPS 投入的地方。
接下来是矢量引擎,它旨在加速矢量运算——每个输出元素都依赖于多个输入元素的运算,例如在注意层中计算 softmax 或在层/批处理规范化层中计算移动平均值和方差时。NeuronCore 调度程序可以并行化,这样所有引擎都可以同时工作。例如在注意层中,矢量引擎可以同时计算当前图块的 softmax,而脉动阵列可以计算 QxK^T matmul 或 AxV matmul。
第三个是标量引擎,它被设计用于执行 1:1 映射的操作,例如元素级操作(如 SeLU)或 Exp,或者在线性层末尾添加偏差。
最后,在 NeuronCore 内部,有多个图灵完备的GpSimd 引擎,可以运行任意 C++,这样任何 C++ 开发人员都可以轻松快速地运行自定义操作。例如,在自注意力层中使用 GpSimd 引擎时,您需要应用三角掩码,以便当前 token 可以看到任何未来的 token,并且只能看到当前和过去的 token。但是,随着Tri Dao 的 Flash-Attention和Horace He 的 FlexAttention推广的 Block Sparse Attention 的出现,随着时间的推移,应用三角掩码可能会变得不那么重要。
此外,与 Trainium1 一样,Trainium2 也有专用的集体通信核心,专门用于与其他芯片通信。这是一项出色的创新,因为它允许计算通信重叠,而不会在计算资源和通信资源之间产生任何争用。
相比之下,在 Nvidia 和 AMD GPU 上,通信操作与计算操作在相同的核心 (SM) 上运行。因此,最终用户需要仔细平衡运行通信操作的 SM 与运行计算操作的 SM 的比例。在 GPU 上,这是使用“ NCCL_MIN_NCHANNELS ”环境标志完成的,实际上这是一个相当复杂的调整。
由于这种复杂性,只有最先进的用户才会进行通信/计算 SM 比率调整。此外,执行通信操作通常会降低运行计算操作的 SM 的 L2 缓存提示率。因此,Nvidia PTX 提供了缓存提示,以便集体通信内核工程师可以告诉 GPU 跳过将其元素存储在 L2 缓存中。
总的来说,我们相信拥有专用的集体通信核心对于优化通信计算重叠来说是一个更清晰的设计。
虽然拥有所有这些专用引擎似乎是一个好主意,因为专用资源比通用资源消耗更少的功率和面积,但它也可能导致瓶颈。必须提前选择各种专用资源的比例,这可能导致这种平衡对于各种不同的工作负载来说是错误的。某些资源总是未得到充分利用,而其他资源总是会限制性能。在某些方面,在工作负载仍在演变时过早地专门化您的架构可能是一个冒险的决定。
服务器架构
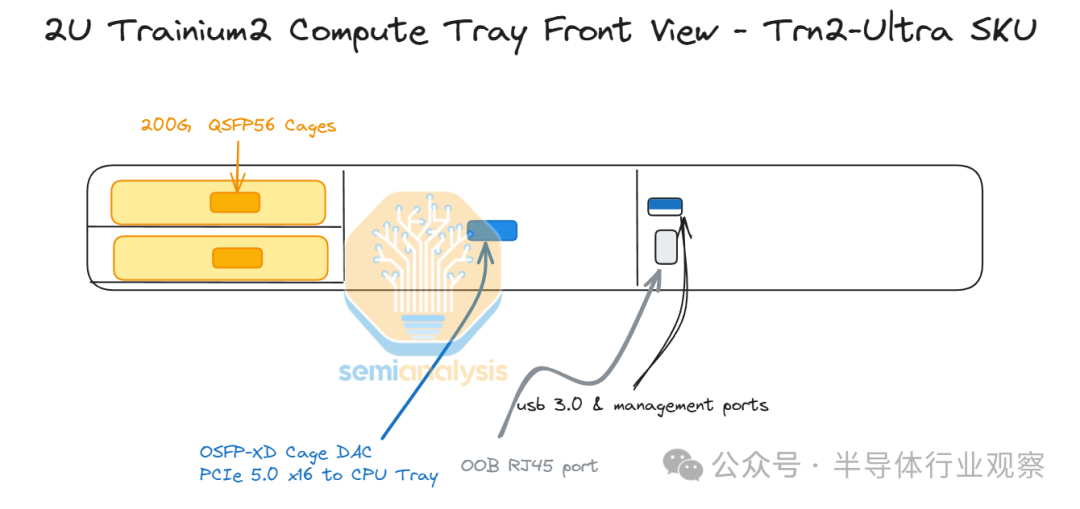
Trainium2 和 Trainium2-Ultra 服务器的构建块就是我们所说的 Trainium2“物理服务器”。每个 Trainium2 物理服务器都有一个独特的架构,占用 18 个机架单元 (RU),由一个 2 机架单元 (2U) CPU 机头托盘组成,该托盘连接到八个 2U 计算托盘。在服务器的背面,所有计算托盘都使用类似于 GB200 NVL36 的无源铜背板连接在一起形成一个 4×4 2D 环面,不同之处在于,对于 GB200 NVL36,背板将每个 GPU 连接到多个 NVSwitches,而在 Trainium2 上,没有使用交换机,所有连接都只是两个加速器之间的点对点连接。
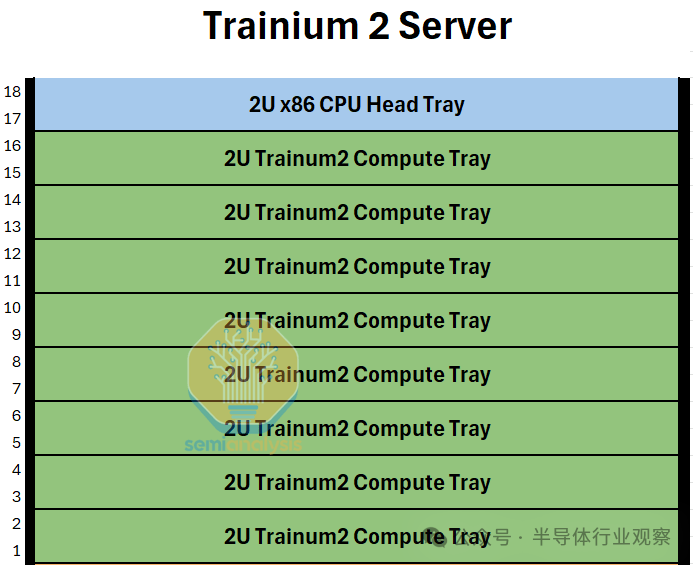
每个 2U 计算托盘都有两个 Trainium 芯片,没有 CPU。这与 GB200 NVL72 架构不同,在 GB200 NVL72 架构中,每个计算托盘都在同一托盘中同时配备 CPU 和 GPU。每个 Trainium2 计算托盘通常也被称为 JBOG,即“一堆 GPU”,因为每个计算托盘都没有任何 CPU,无法独立运行。
因此,每台 Trainium2 服务器可容纳 16 个 Trainium2 芯片。两台 16 芯片 Trainium2 服务器可装入一个机架。对于 Trainium2-Ultra SKU,每台服务器由四台物理服务器组成,每台物理服务器有 16 个芯片,因此总共可容纳 64 个芯片,占用整整两个机架。我们将更详细地描述机架布局,并在下方提供立面图。
每个计算托盘通过服务器正面的外部 PCIe 5.0 x16 DAC 无源铜缆连接到 CPU 托盘。
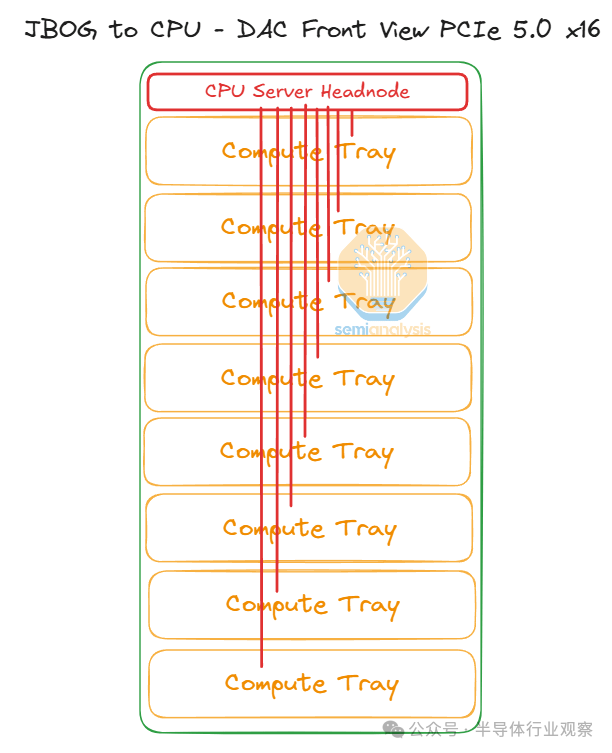
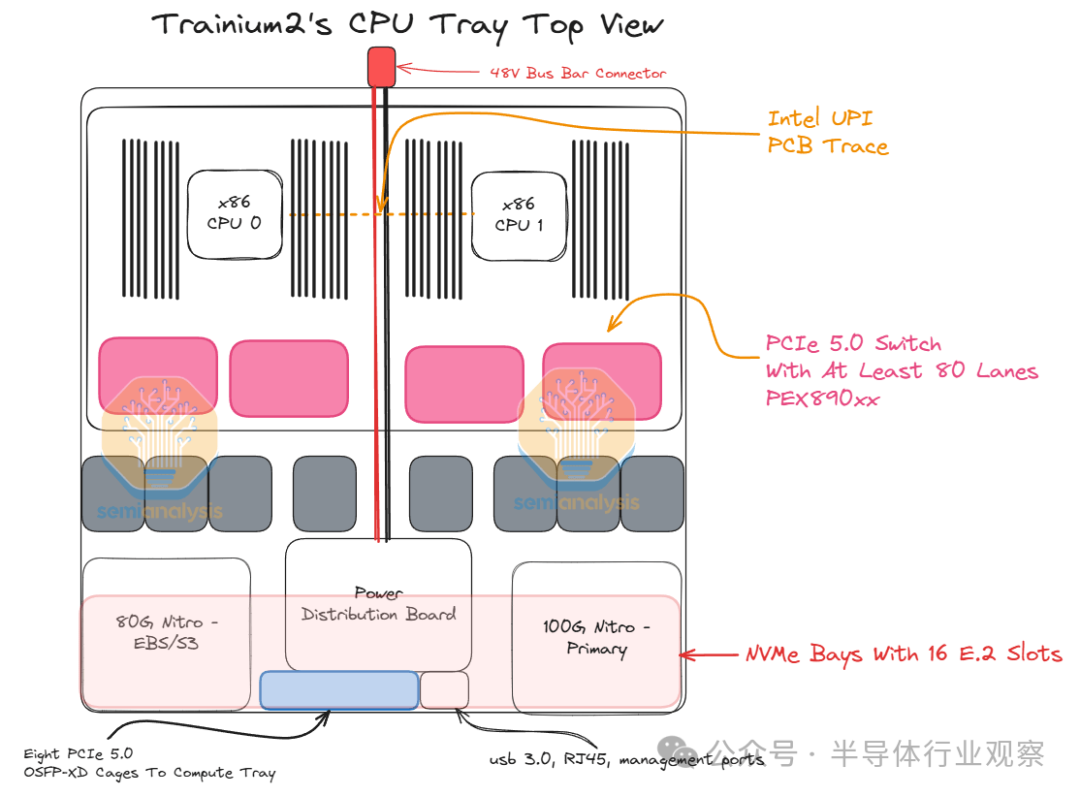
CPU 托盘(Tray)
CPU 托盘内部有 PCIe 交换机,用于将计算托盘与本地 NVMe 磁盘连接起来,这样 Trainium2 就可以使用 GPUDirect-Storage 访问存储,而无需通过 CPU。
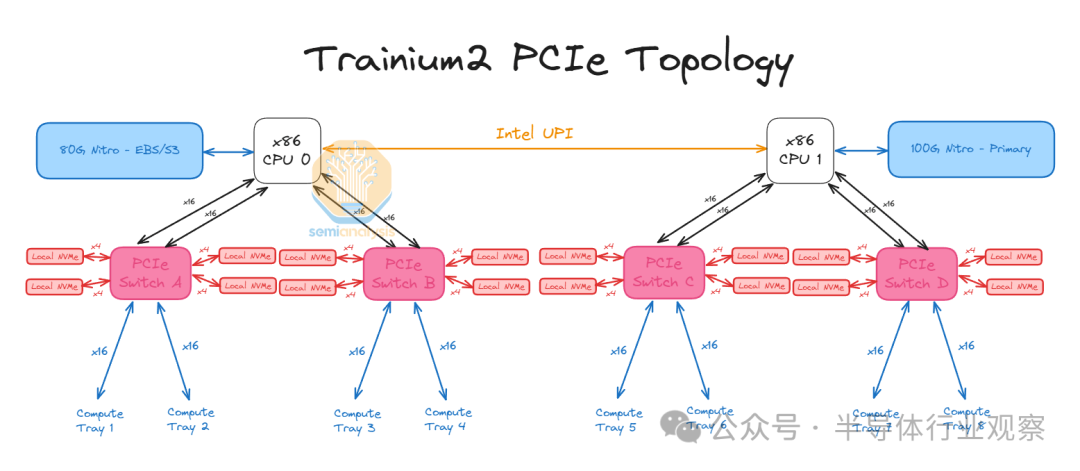
每台服务器共有 16 个本地 NVMe,它们都可以通过 Trainium2 芯片直接访问。此外,还有连接到主 CPU0 的标准 80Gbit/s 弹性块存储链路和用于 AWS 前端网络的主 100Gbit/s Nitro 卡,称为弹性网络适配器 (ENA)。
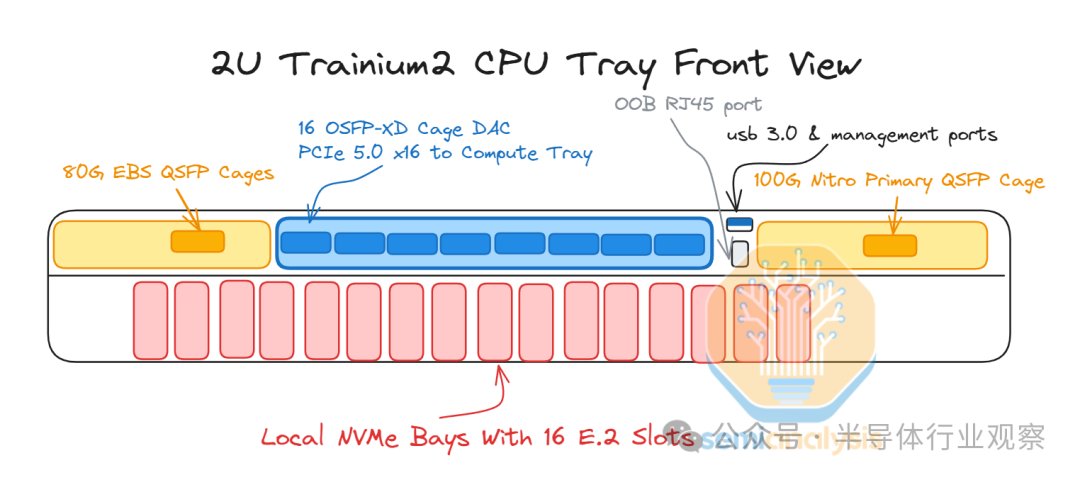
每个 CPU 托盘包含两个 Intel Xeon Sapphire Rapids CPU 和 32 个用于 DDR5 RAM 的 DIMM 插槽,最多可容纳 2 TB 的 CPU 内存,并使用类似的机架级 48V DC 母线配电系统。
计算托盘
正如文章开头提到的,有两个 SKU:
Trainium2 (Trn2)
Trainium2-Ultra (Trn2-Ultra)
我们首先来谈谈普通 Trn2 Trainium2 实例的计算托盘。每个 Trn2 计算托盘在 PCB 上有两个 Trainium2 芯片,并有 6 个服务器内扩展铜背板连接器,用于连接到同一服务器中的其他计算托盘。
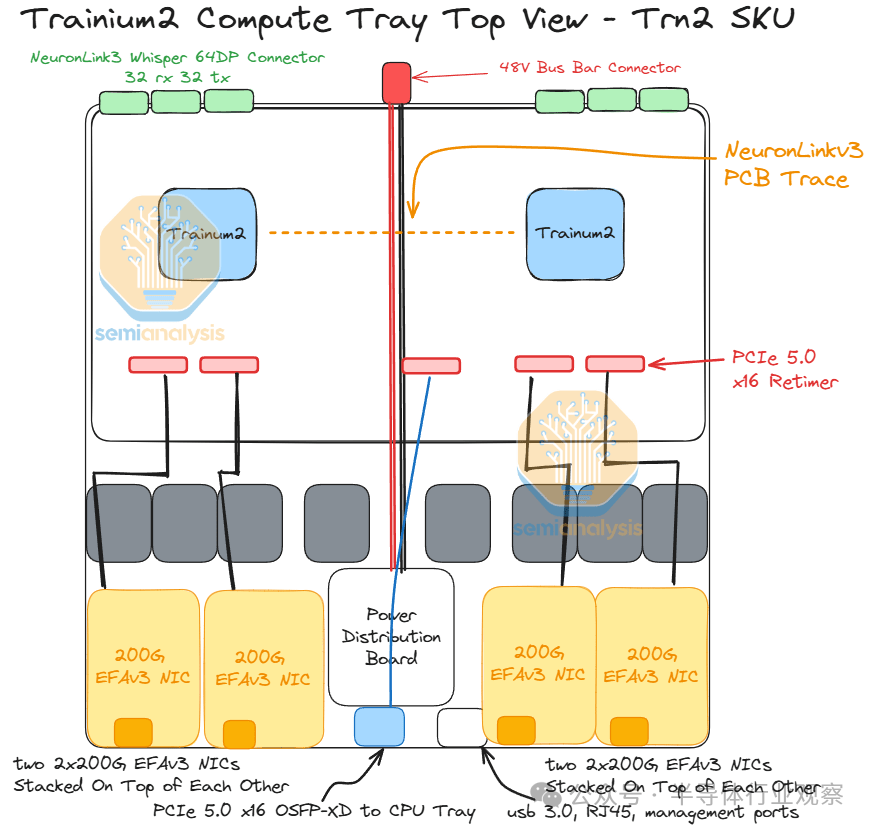
此外,对于 Trn2,每个计算托盘最多有 8 个 200G EFAv3 NIC,每个芯片可提供高达 800Gbit/s 的横向扩展以太网网络。从计算托盘连接到 CPU 托盘的笼子也需要一个重定时器。计算托盘左侧的 Trainium2 芯片将使用连接到 CPU 托盘的前 8 个通道,而右侧的 Trainium2 芯片将使用连接到 CPU 托盘的后 8 个通道。
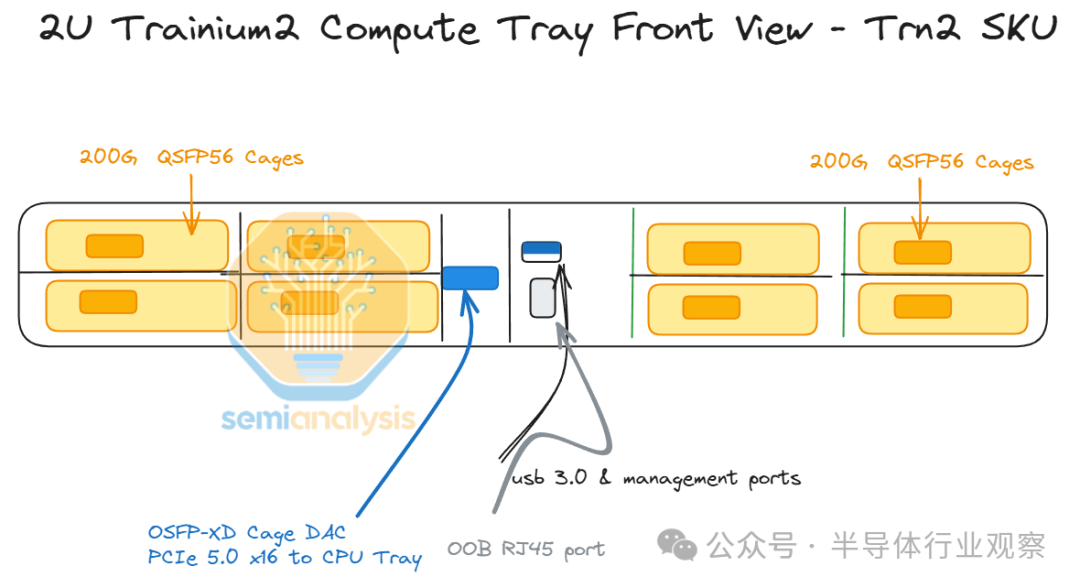
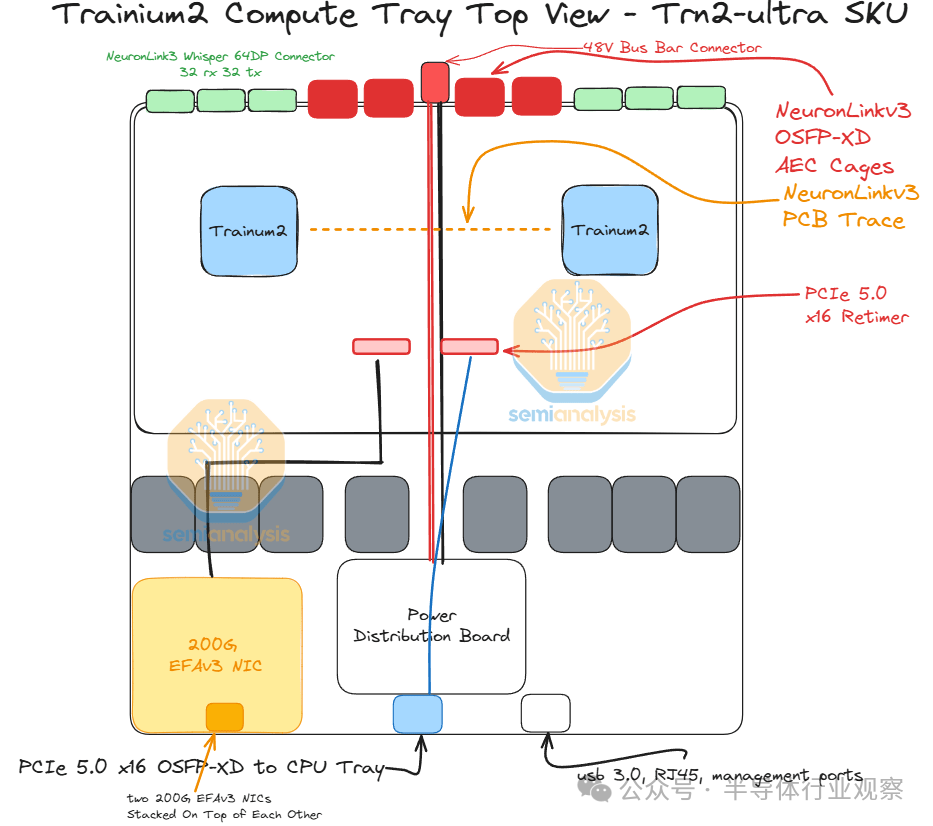
Trn2-Ultra SKU 与普通 Trn2 SKU 非常相似,但 Trainium2 芯片上用于横向扩展网络的 PCIe SerDes 通道较少,Trn2-Ultra 芯片的横向扩展带宽仅为 200Gbit/s,而 Trn2 芯片的横向扩展带宽为 800Gbit/s。这些通道用于将 4 台物理服务器(每台 16 个芯片)连接在一起,形成一个 64 台的纵向扩展网络。纵向扩展网络将在每个芯片上实现两个 16 通道 OSFP-XD 笼(cages),有源电铜缆将插入其中,以将四台每台 16 个芯片的物理服务器连接在一起,使 Trn2-Ultra 服务器的横向扩展规模达到 64 个芯片。
系统/机架架构
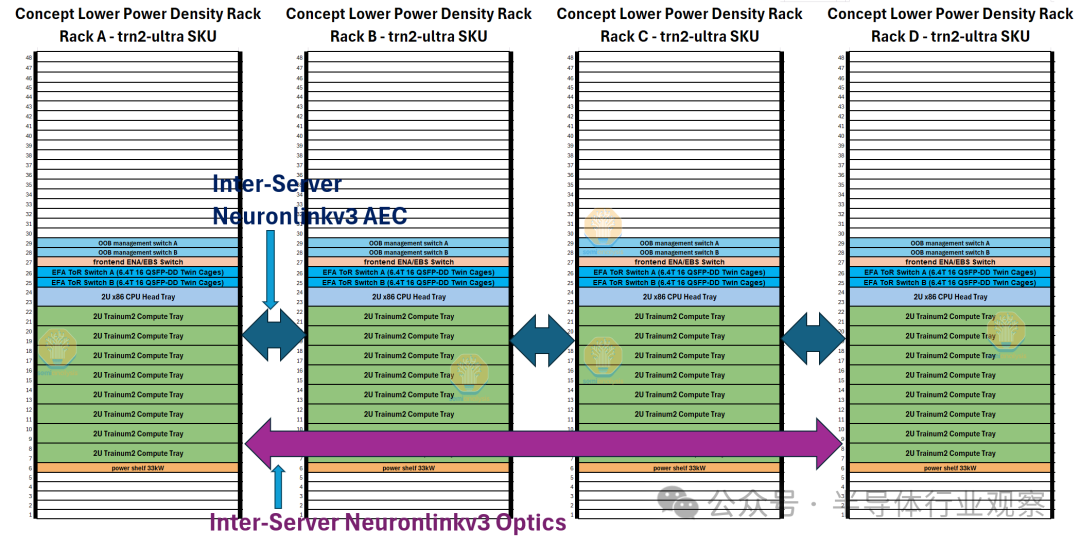
继续讨论系统/机架架构,我们首先讨论普通的 Trn2 SKU。每个机架将考虑两台 Trn2 服务器和四台 12.8T ToR EFAv3 以太网交换机,以提供每芯片高达 800Gbit/s 的横向扩展带宽。该机架使用类似的 48V DC 母线架构,交流到直流的转换发生在机架级,而不是每个机箱单独执行转换。
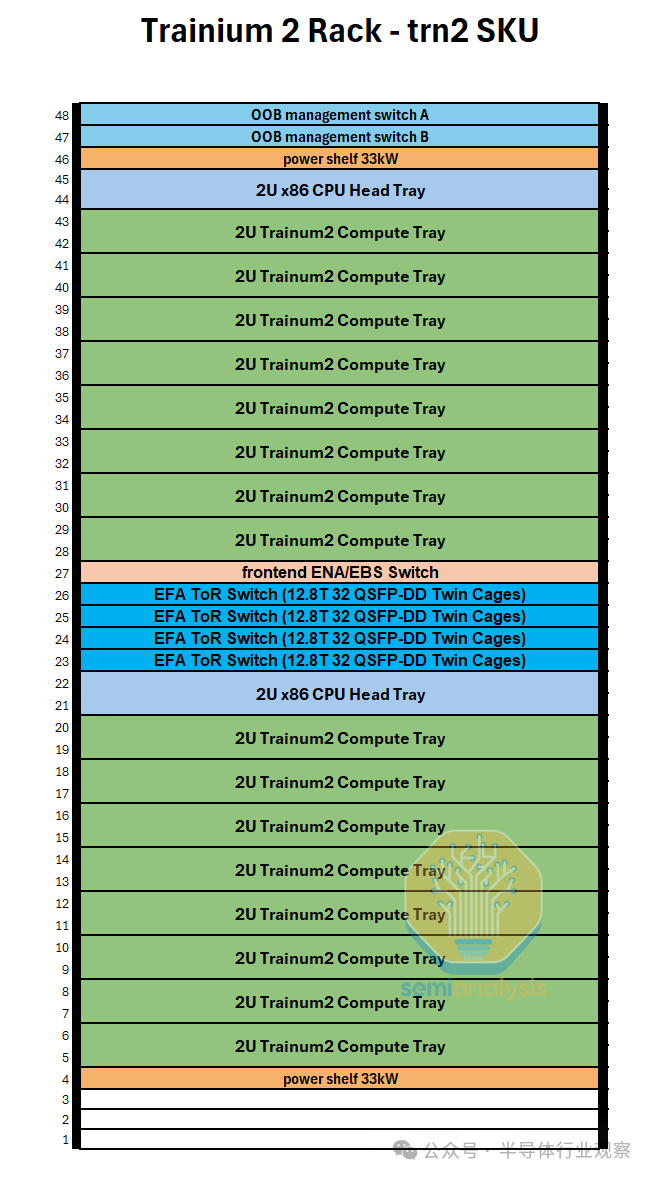
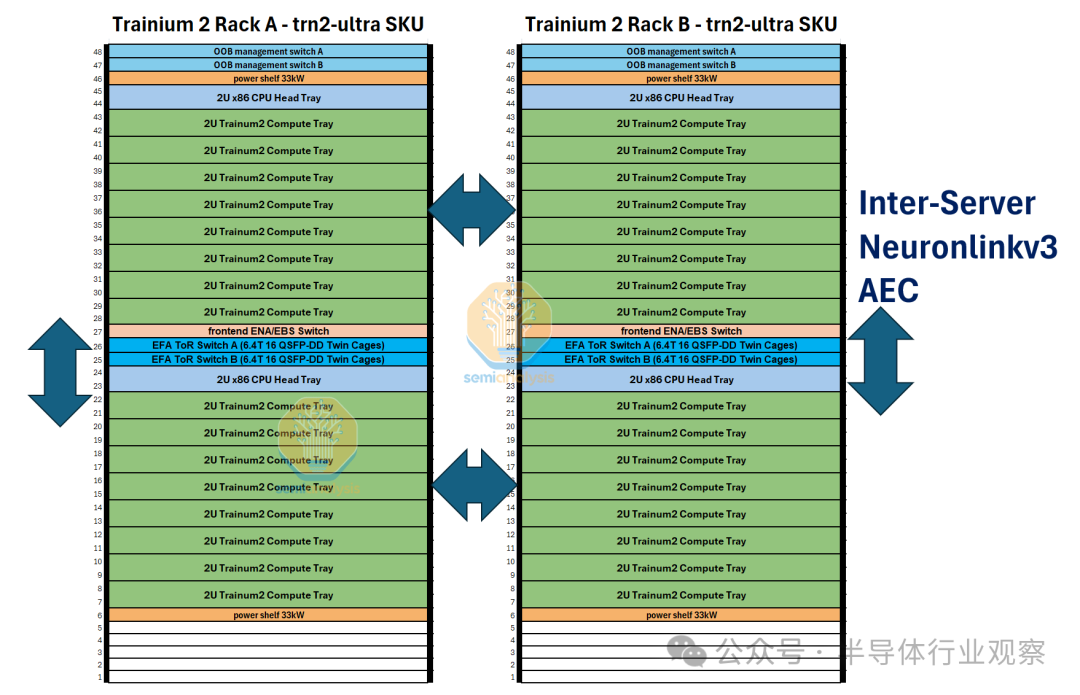
Trn2-Ultra SKU 由每个扩展域 4 个 16 芯片物理服务器组成,因此每个扩展域有 64 个芯片,由两个机架组成,配置类似于 GB200 NVL36x2。为了沿 z 轴形成一个圆环,每个物理服务器使用一组有源铜缆连接到另外两个物理服务器。
功率预算
我们估算了每个 SKU 的机架功率,Trn2-Ultra 64-Chip 服务器内的两个机架中的每一个都需要 24kW 的功率(每个 Trn2-Ultra 64-Chip 服务器 48kW)。
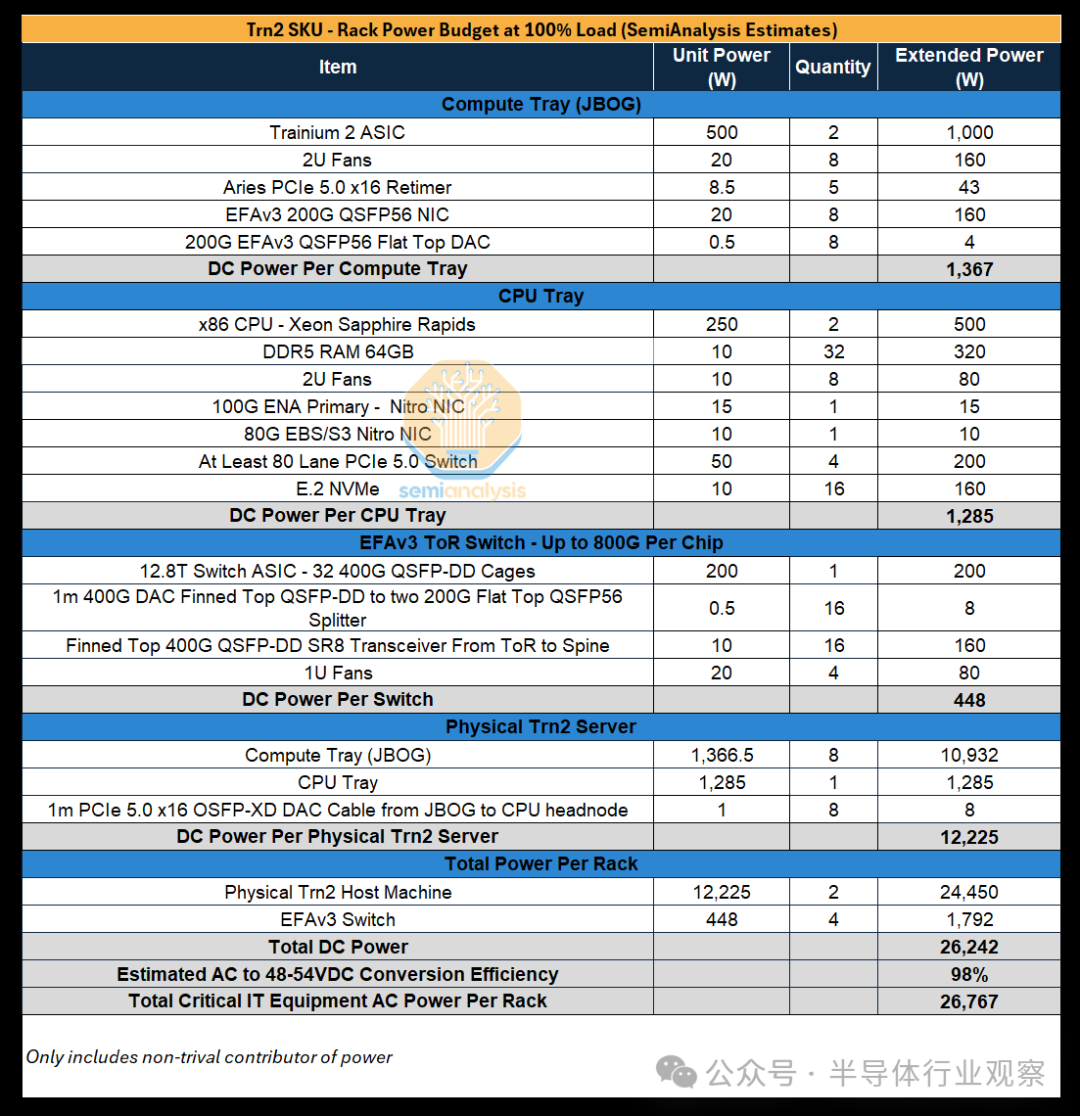
用于放置普通 Trn2 服务器的机架的机架密度为 27kW,但请记住,一个机架中将放置两台 16 芯片 Trn2 服务器。放置 Trn2 服务器的机架的功率密度更高,这是因为需要额外的 NIC 和使用更多更高基数的 ToR 交换机来支持每个 Trainium2 芯片的横向扩展网络高达 800Gbit/s,与 Trn2-Ultra 服务器的额外服务器间 AEC NeuronLinkv3 电缆相比,这会消耗更多电力。
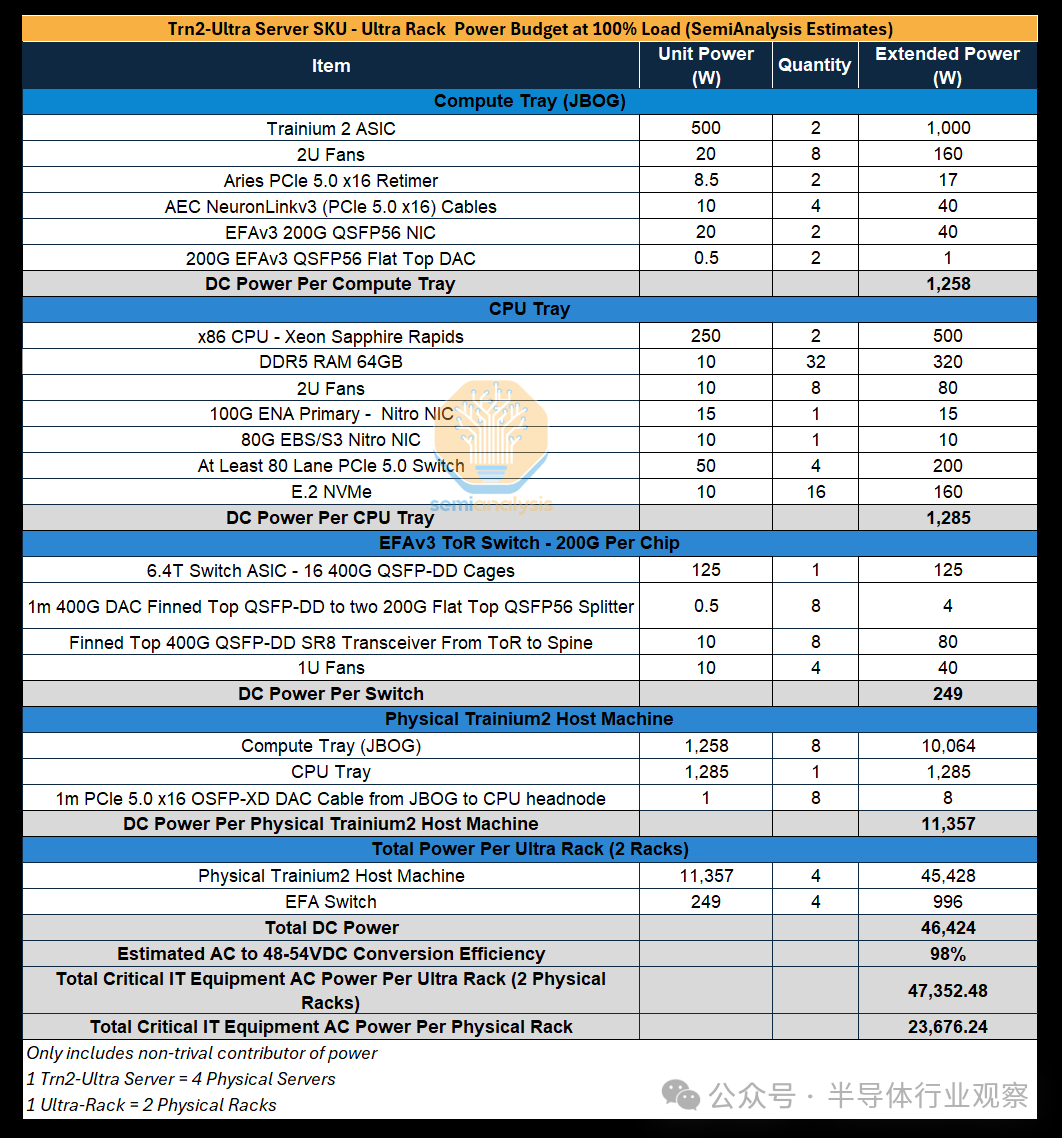
Rainier 项目 – 400k Trainium2 集群
我们认为,最大的 Trainium2 集群部署之一将在印第安纳州。在这里,AWS 目前正在为 Anthropic 部署一个名为“Project Rainier”的包含 40 万个 Trainium2 芯片的集群。
该园区已完成第一期建设,目前共有七栋建筑,每栋建筑的 IT 电力为 65MW,总计 455MW。印第安纳州 AWS 园区的第二期将再增加九栋 65MW 建筑,总电力为 1,040MW。我们认为该园区的 PUE 约为 1.10-1.15,因为园区位于印第安纳州北部。除了 Trainium2 部署外,该数据中心园区还将与 AWS 传统的面向 CPU 的服务器以及 AWS 的 Blackwell 集群部署共享。
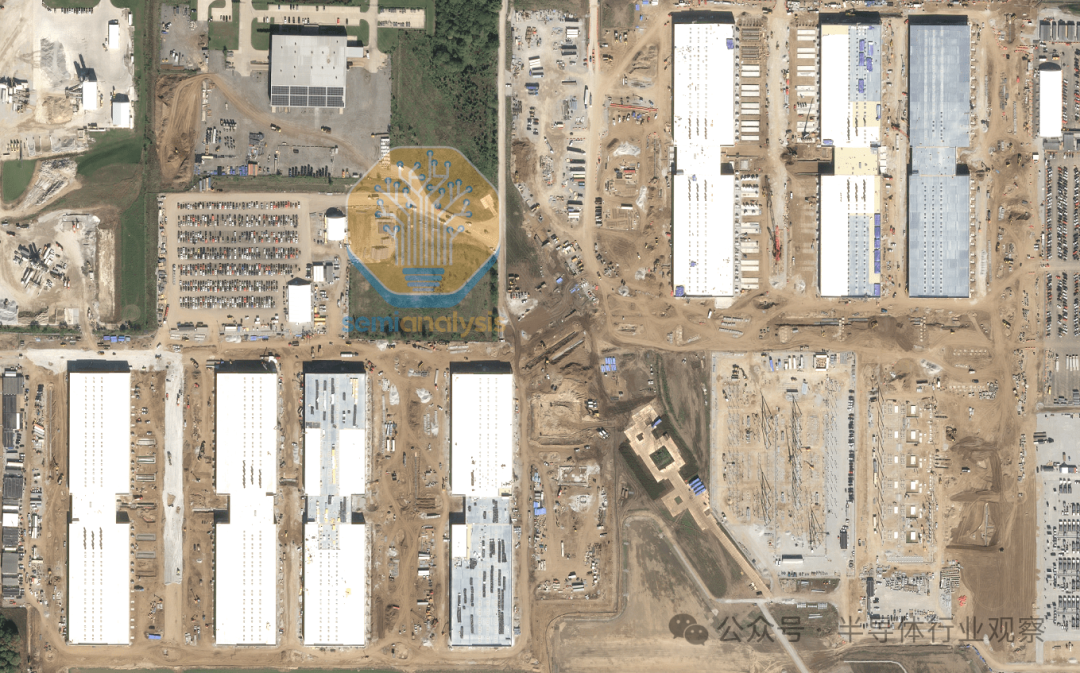
我们认为 AWS 将在包含 16 个机架的封闭舱中部署 Trainium2 机架,并在封闭舱的末端额外部署 4 个机架,用于网络交换机、管理交换机和其他服务器。冷空气将通过服务器的前部,而服务器的后部将热空气排入烟囱。
请注意,400k Trainium2 的原始 flops 比 100k GB200 集群要少。这意味着 Anthropic 将很难与竞争对手 100k GB200 集群匹敌,因为 Amdahl 定律会吞噬它们。在 400k Trainium2 和 EFA 上进行所有缩减将非常困难,因此 Anthropic 需要在异步训练方面取得一些相当大的创新进步。
网络概述
我们上面已经提到并讨论了网络难题的各个部分,但本节将全面解释 Trainium2 架构中使用的所有网络。
基于 Trainium2 的实例有四种不同类型的网络:
1.扩大规模:NeuronLinkv3
(A)服务器内 NeuronLinkv3
(B)服务器间 NeuronLinkv3
2.横向扩展:Elastic Fabric Adaptor EFAv3
3.前端和存储:弹性网络适配器 (ENA)、弹性块存储 (EBS)
4.带外管理网络
NeuronLinkv3 是一个扩展网络,相当于 Nvidia 的 NVLink 互连的 AWS 版本。与 Nvidia 的 NVLink 互连不同,NeuronLinkv3 分为两种类型:服务器内和服务器间。服务器内将每个物理服务器内的 16 个芯片连接在一起,而服务器间 NeuronLink 将来自不同物理服务器的芯片连接在一起,总共 64 个芯片。每个芯片将具有 640GByte/s 的单向带宽,最多可有 6 个直接邻居。
与 NeuronLinkv3 有限的 64 个芯片世界大小相比,EFAv3 后端/计算结构用于将通信从数十个机架扩展到数千个机架。尽管 EFAv3 可以将更多芯片连接在一起,但缺点是它比 NeuronLink 网络慢得多。在 Trn2 SKU 上,EFAv3 结构慢 6.4 倍,在 Trn2-Ultra SKU 上,EFAv3 结构慢 25.6 倍。
快速回顾一下,前端网络只是一个普通的以太网网络,用于连接到互联网、SLURM/Kubernetes 和网络存储以加载训练数据和模型检查点。每个包含一个 CPU 托盘的 16 个芯片的物理服务器都有 100Gbit/s 的 ENA 前端网络和 80Gbit/s 的专用 EBS 块存储网络。
最后,还有带外管理网络。它用于重新镜像操作系统,监控节点健康状况,如风扇速度、温度、功耗等。服务器、PDU、交换机、CDU 上的基板管理控制器 (BMC) 通常连接到此网络,以监控和控制服务器和各种其他 IT 设备。
在接下来的章节中,我们将深入探讨并详细解释上述一些网络主题和结构。
NeuronLinkv3 扩展网络
每个 Trainium2 物理服务器都有一个铜背板,其中每个芯片使用 JBOG PCB 板上的 PCB 走线连接到另一个芯片(即左侧 Trainium2 芯片连接到同一 JBOG 上的右侧 Trainium2 芯片),并且每个芯片还使用铜背板连接到其他三个服务器内芯片。NeuronLinkv3 基于 PCIe Gen 5.0,这意味着每条通道 32Gbit/s(单向)。
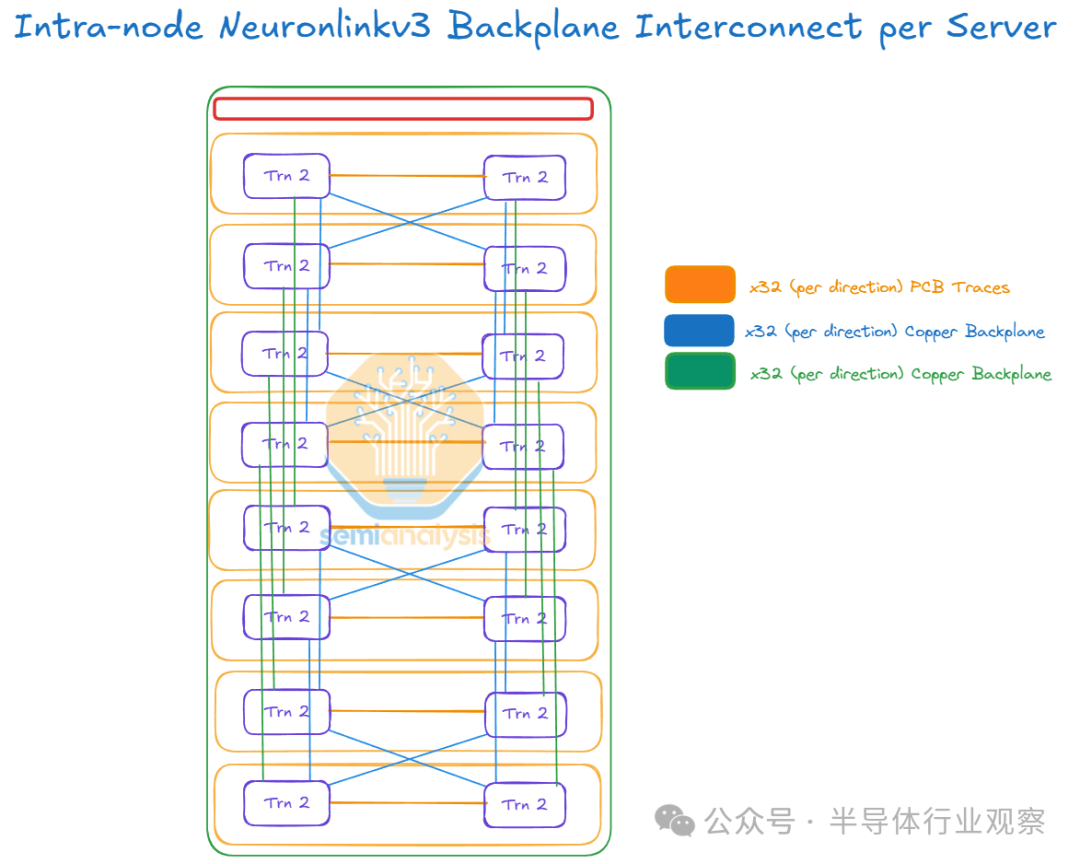
每个芯片使用 32 个 PCIe 通道连接到其他服务器内芯片,这意味着每个芯片以 128GByte/s(单向)的速度与其每个服务器内邻居通信。服务器内 NeuronLinkv3 是一个 2x2x2x2 超立方体网格。
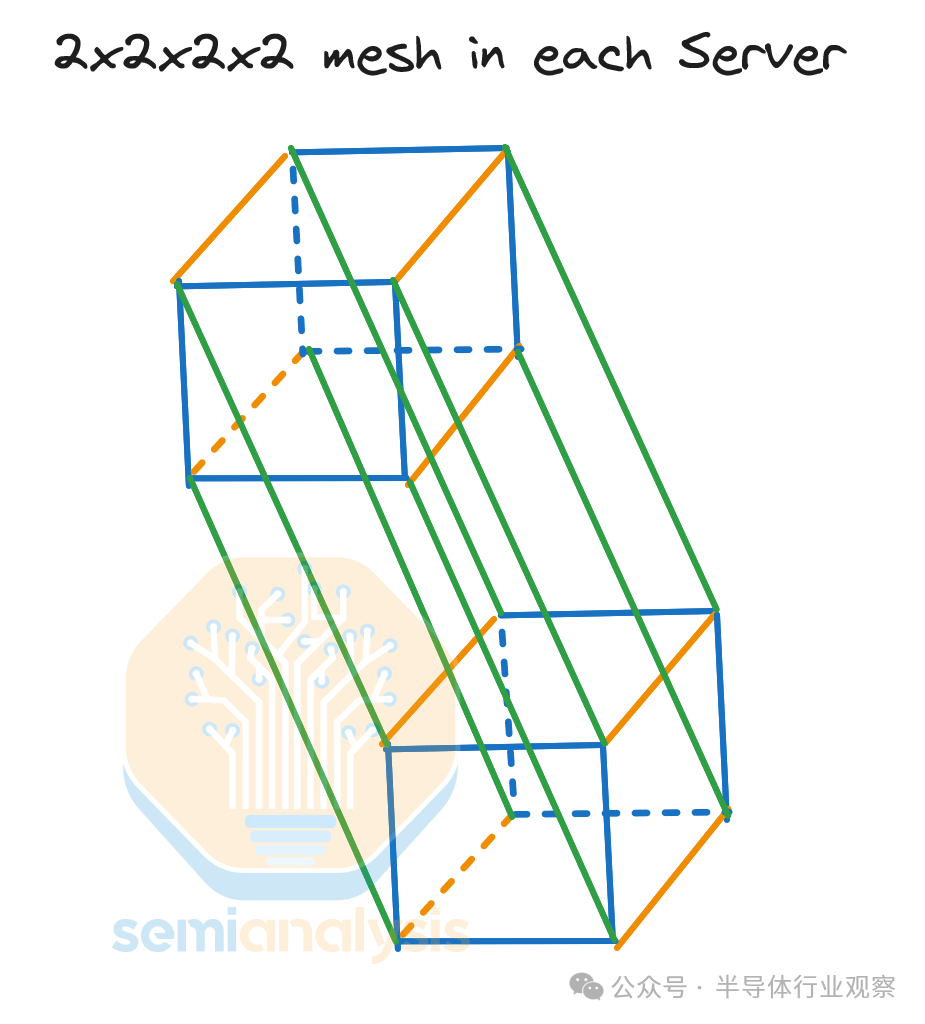
2x2x2x2 超立方体 == 4×4 环面的同构证明
有趣的是,2x2x2x2 4D 超立方体与 4×4 2D 环面同构,这意味着每个 Trainium2 物理服务器都是一个 4×4 2D 环面。
同构的数学证明非常简单。我们只需要检查顶点和边的总数是否相同,并且每个顶点在每个图中都有相同数量的橙色、蓝色和绿色邻居。我们可以在下面的可视化中清楚地看到,两个图都有 16 个顶点、32 条边,并且两个图中的每个顶点都有一条橙色边、一条绿色边和 2 条蓝色边。由于它们满足所有这些条件,因此它确实是同构的。
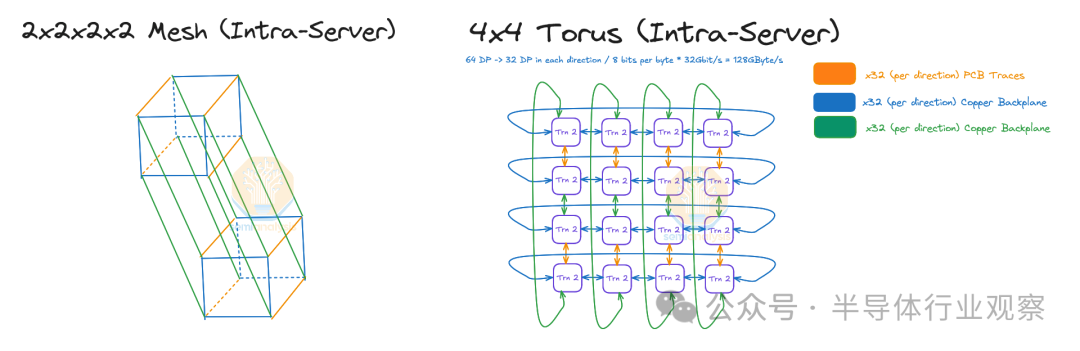
服务器间 NeuronLinkv3 扩展
在 Trainium2 Trn2-Ultra SKU 中,四台物理服务器连接在一起,形成一个“超级服务器”,在扩展域内有 64 个芯片。这 64 个芯片连接在一起形成一个 4x4x4 3D 环面,其中 Z 轴的点对点带宽仅为 64GByte/s,而 x 轴和 y 轴上的点对点带宽为 128GByte/s,点对点带宽是后者的两倍。每个芯片使用 OSFP-XD 有源电缆连接到其他物理服务器中的另外两个芯片。这样,芯片就能够形成一个在 Z 轴上具有环绕连接的链(物理服务器 A -> 物理服务器 B -> 物理服务器 C -> 物理服务器 D -> 物理服务器 A)。
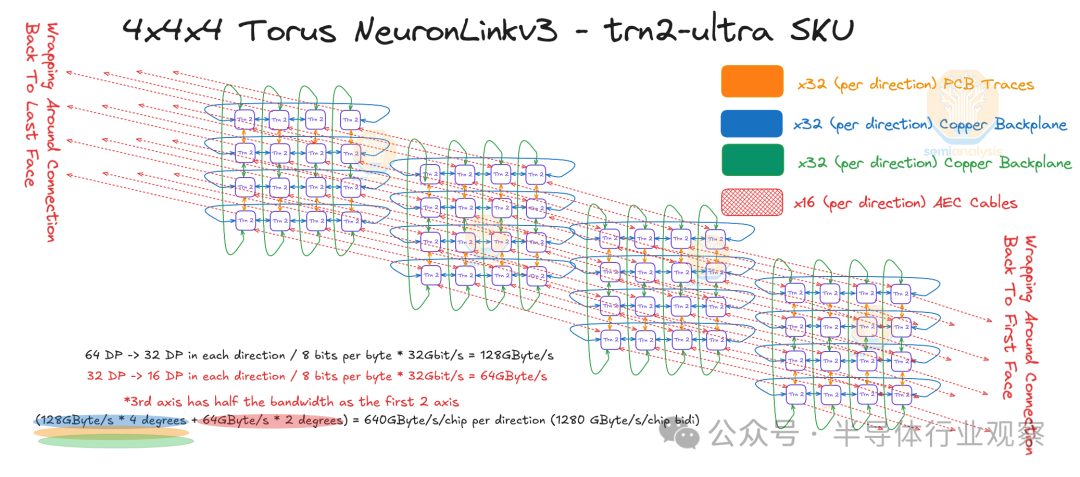
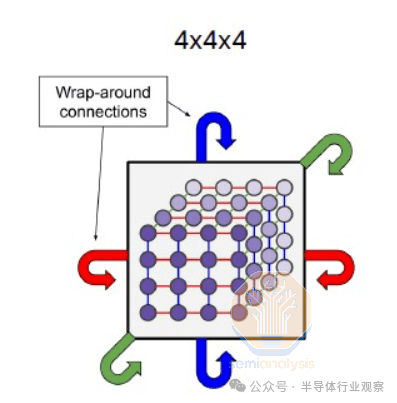
这个 4x4x4 3D 圆环与 TPU 立方体机架设计非常相似,后者也是 4x4x4 3D 圆环,并且在所有 3 个轴上都具有对称的点对点带宽。Trainium2 拓扑和 TPU 拓扑之间的另一个区别是,TPU 立方体可以通过光学器件在所有六个面上与其他 TPU 立方体连接,而 Trainium2 不允许这样做。
由于 PCIe 物理层允许在 NIC 和 NeuronLinkv3 之间重新分配,Amazon 和 Anthropic 可能在扩展带宽和扩展带宽之间达成了妥协。Trainium2 仅有足够的 NeuronLinkv3 通道来创建一个 4x4x2 3D 圆环,其世界大小为 32,并且在所有 3 个轴上具有对称的点对点带宽,但对于前沿 LLM 训练和推理来说,具有不对称 BW 的世界大小为 64 可能比较小的 32 世界大小要好得多。
无 NeuronLinkv3 PCIe 光学元件
由于每个机架有两个物理服务器,因此物理服务器能够在不到 2 米的距离内形成一个环,因此可以保持在 PCIe AEC 的范围内。
如果 AWS 设计的 Trainium2 架构具有较低的机架功率密度,因此每个机架只能容纳一台服务器,那么他们就必须创建一个四物理服务器环来形成一个 64 芯片超级服务器,然后 AWS 将需要使用 PCIe 光纤,因为最长的连接现在将跨越四个机架,超出了 PCIe AEC 的范围。
与实际选择的设计(使用更便宜、更可靠的 AEC)相比,引入 PCIe 光学器件会导致 NeuronLinkv3 服务器间网络的可靠性下降和成本增加。
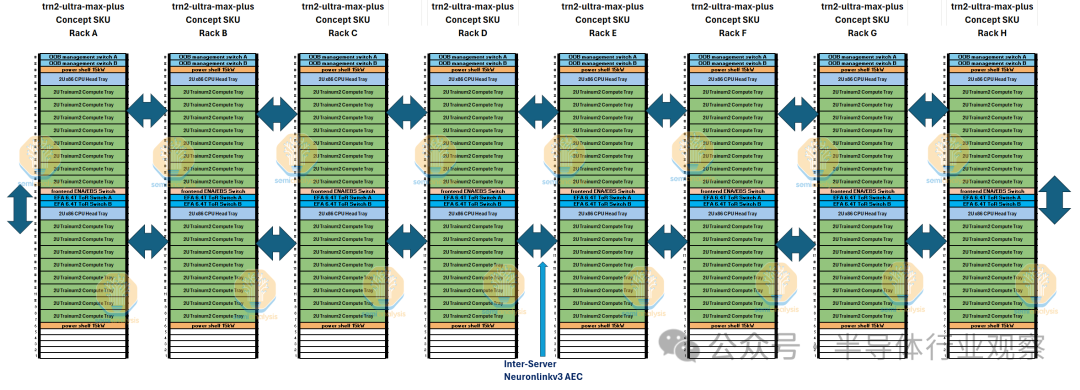
Trn2-Ultra-Max-Plus 4x4x16 概念 SKU
由于 NeuronLink 服务器间架构是一个 3D 环面,且沿 z 轴的第5和第6 个邻居上有 AEC 连接,因此我们相信可以沿着热通道遏制侧内的物理服务器行将 z 轴从 4 台服务器扩展到 16 台服务器。
我们提出了一个名为“trn-2-ultra-max-plus”的概念 SKU,它将 256 个芯片连接在一起,形成一个 4x4x16 3D 圆环,而不是通用版 Trn2-Ultra SKU 中的 64 个芯片。此概念 SKU 中的点对点带宽在 x 和 y 轴上仍为 128GByte/s,在 z 轴上仍为 64GByte/s。
我们认为,在需要使用 PCIe 光纤连接单个热通道遏制区外的机架排之前,256 个芯片将是 AEC 和无源铜缆可以达到的最大范围。
这种更大规模的世界规模将允许更有效地训练无法容纳在单个 Trn2-Ultra 64 芯片服务器中的相对较大的模型。这个概念的一个缺点是,这意味着许多芯片将以点对点拓扑(如圆环)永久地相互连接。
工作爆炸半径(Job Blast Radius)
当许多芯片以点对点环形拓扑连接在一起时,如果环形中只有一个芯片发生故障,整个环形扩展域就会变得毫无用处。这会导致吞吐量不佳,就像 TPUv2 pod 和 TPUv3 pod 中看到的那样。对于 Trn2-Ultra,如果 Trn-2-Ultra 服务器中的 64 个芯片中只有一个发生故障,则所有 64 个芯片都将无法做出任何有用的工作。在我们的概念 SKU trn2-ultra-max-plus 中,假设有 256 个芯片连接在一起,如果 256 个芯片中只有一个发生故障,则所有256 个芯片都将被视为故障。
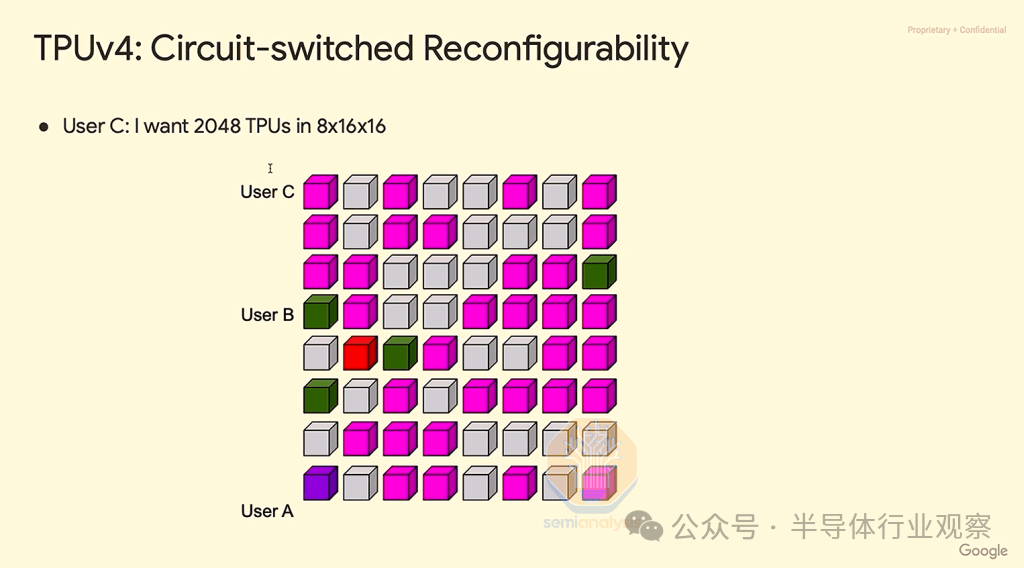
对于 TPUv4,Google 针对这一巨大的作业爆炸半径问题推出了解决方案。该解决方案是在 4x4x4 圆环立方体之间使用可重构光开关,将每个芯片故障的爆炸半径限制在 64 个芯片以内,尽管扩展后的 pod 大小为 4k。
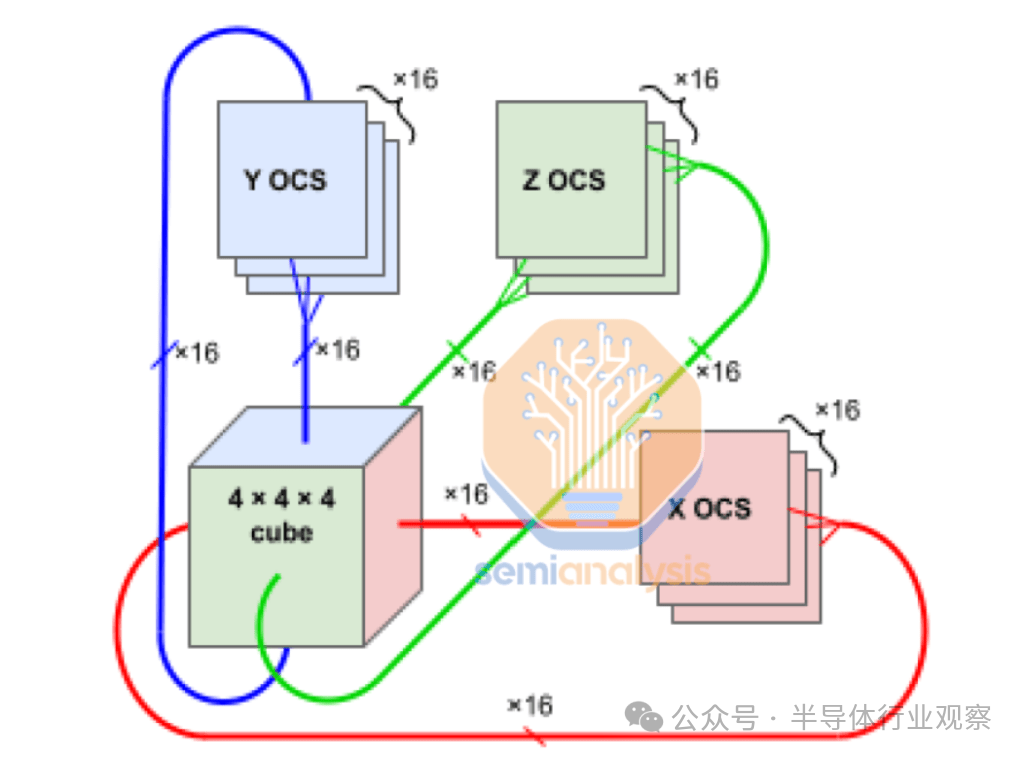
正如您在下面的 TPU pod 立方体地图中看到的,不同的用户可以形成一个 3D 圆环,围绕发生故障的立方体(红色立方体)进行路由。虽然这是一个聪明的解决方案,但我们认为 AWS 并没有选择在每个 4x4x4 立方体之间使用 OCS 来实现巨大的世界规模,因为从软件和硬件的角度来看,OCS 的部署非常复杂,并且涉及使用昂贵的光学器件。光纤链路需要收发器,由于需求量大,收发器仍然短缺,而且每带宽的成本通常比无源 DAC 铜缆高 10 倍。正是由于这种非常高的光学成本,您会看到 TPU 立方体内大多使用 DAC 铜缆,这也是 Nvidia GB200 NVL72 也在其扩展网络中使用铜缆的一个关键原因。
虽然在立方体中,单个芯片故障意味着整个立方体停止服务,但芯片之间的网络链路故障通常可以绕过。话虽如此,我们期望网络链路具有较高的可靠性,因此我们不希望 Trainium2 NeuronLinkv3 网络链路发生故障或出现太多波动,因为所有链路都使用无源铜缆和有源铜缆。
光收发器与无源和有源电铜缆上的网络连接的平均故障时间 (MTTF) 存在巨大差异。由于收发器激光器故障,MTTF 可能为 100 万至 1000 万小时,而对于铜缆,典型的 MTTF 约为 1 亿小时,可靠性率高出 10 至 100 倍。
可能比更长的 MTBF 更重要的是,与光学系统相比,无源/有源铜缆的抖动可能性要低几个数量级。抖动是光学系统中的常见问题,由于激光器和/或模块过热问题,链路会中断一段时间,时间范围从几微秒到几秒不等。抖动会给依赖稳定网络在芯片之间进行通信的训练任务带来巨大问题。

由于 TPU 在立方体之间使用光学链路,因此当收发器和/或 OCS 发生故障时,Google 必须创建容错路由。有了容错路由,整个 Pod 就不会因为光学链路中断而停止服务,而是在 LLM 训练工作负载下,Pod 仍能以较小的速度运行。与立方体不做任何有用工作相比,这种速度的轻微下降对于整个物理 TPU 系统的有效吞吐量来说非常有利。
然而,值得注意的是,容错 TPU 路由仅有助于处理断开的链接,但是当出现芯片级故障时,由于 JAX/Pytorch 需要具有 0 个孔的长方体形拓扑,这仍然会导致 64 个芯片的爆炸半径。
我们认为,实际上 Trainium2 不需要实施容错路由,因为 NeuronLink 故障几乎为零,因为链路运行在无源和有源铜缆上,这将使链路可靠性比 TPU 交叉立方体光学系统高出 100 倍。如果出于某种原因,这些无源和有源铜缆链路开始成为重大错误来源,那么 Trainium2 Neuronx 集体团队将需要开始实施容错路由。
EFAv3 横向扩展以太网网络
对于 Trainium2,为了在单个互连集群中扩展到数万个芯片,AWS 将使用其内部以太网版本,称为 Elastic Fabric Adapter Version (EFAv3)。这将支持普通 Trn2(16 个芯片)实例每芯片高达 800Gbit/s 的 EFAv3 BW 和 Trn2-Ultra(64 个芯片)每芯片 200Gbit/s 的 EFAv3 带宽。如上所述,Trn2-Ultra SKU 将成为用于最大边界训练和推理工作负载的最常见实例。与 EFAv2 NIC 巨大的 9 微秒数据包延迟相比,EFAv3 NIC 具有较低的 6.5 微秒数据包延迟。数据包延迟是决定集体算法带宽运行速度的主要因素之一。我们将在即将发表的 NCCL 集体深入探讨文章中更详细地解释这些概念。
与 Nvidia 参考网络设计不同,亚马逊目前不会使用铁路优化网络。这意味着服务器上的所有芯片都将连接到同一机架中的同一直接交换机,称为“机架顶部”(ToR)网络设计。
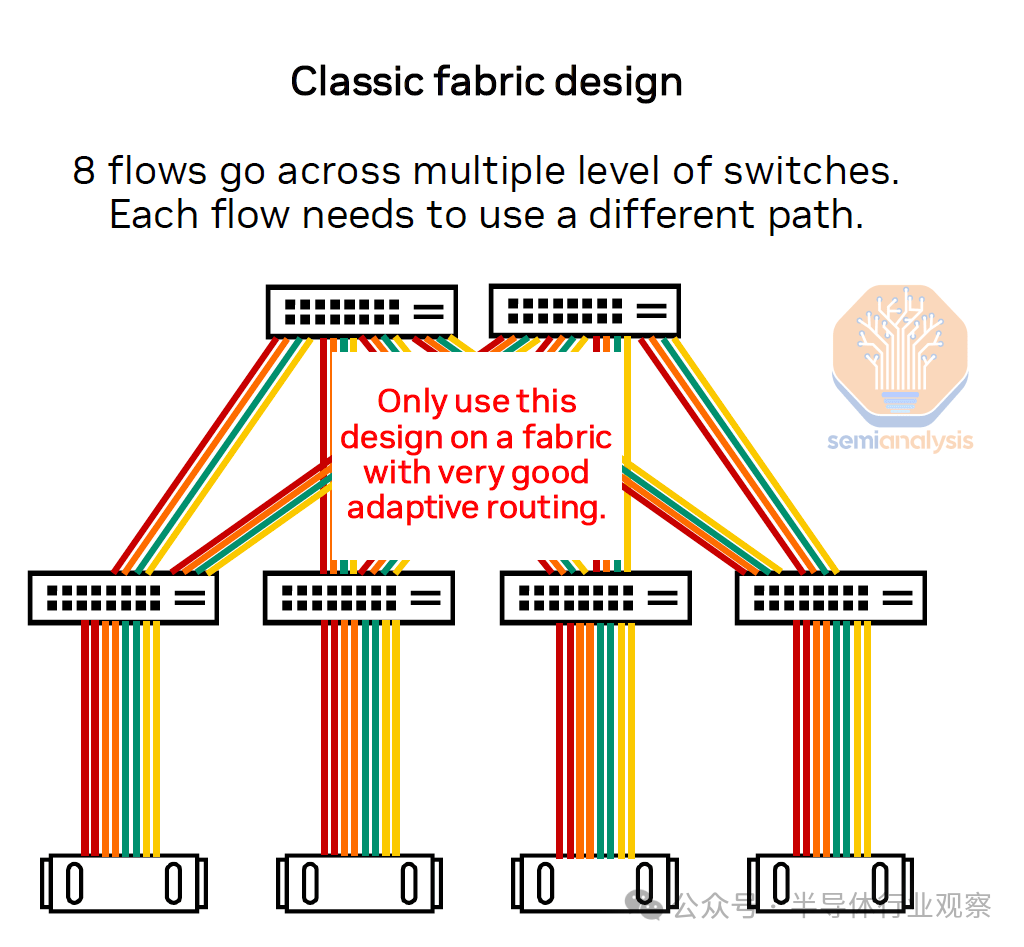
这意味着,与大多数流量只有一跳的轨道优化拓扑相比,平均而言,每个流量在整个网络中需要更多的跳数。在 ToR 设计中,必须有非常好的自适应路由,以避免不同并发流量之间的路径冲突。诸如在队列对 ID 中而不是标准元组中进行哈希处理之类的技术将允许增加网络中的熵,以限制流量冲突的数量。
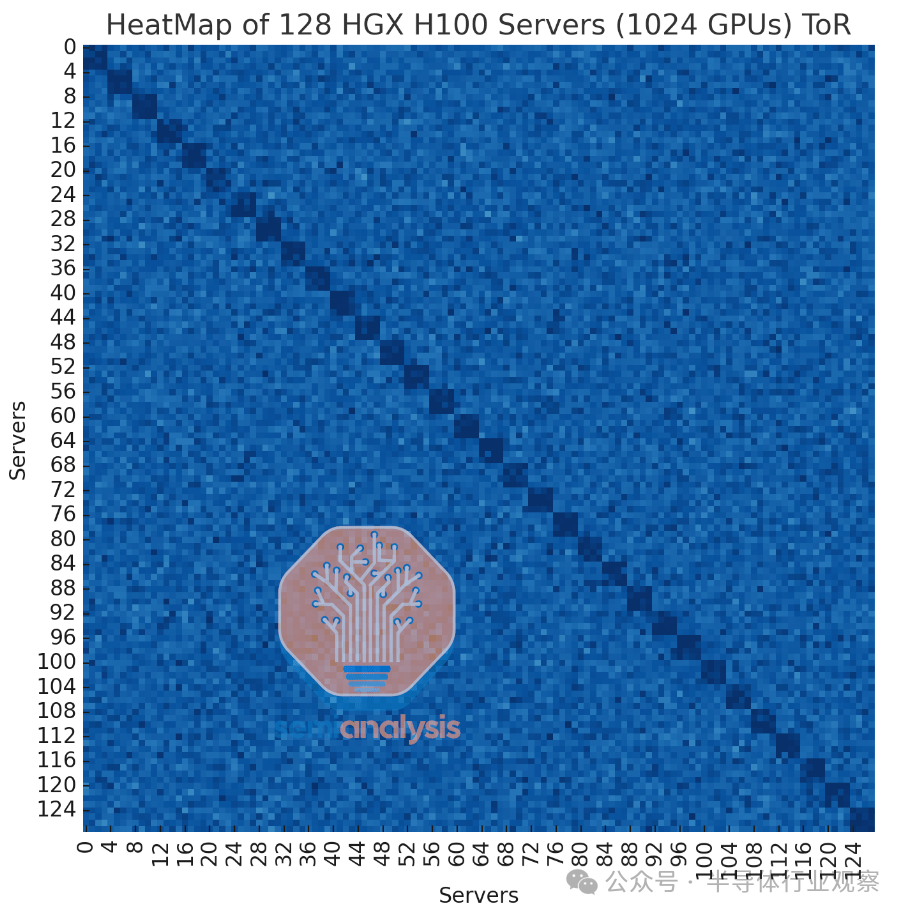
下图显示了我们模拟的这种无阻塞机架顶部结构的热图,其中浅蓝色表示由于拥塞导致带宽减少,深蓝色表示接近满线速率。如您所见,使用 ToR 拓扑可以达到线速率,但由于所有 8 个流都进入一个交换机,因此仍然存在相当大的拥塞,吞吐量变得更加不稳定,拥塞严重导致这些流的带宽减少。
尽管 ToR 网络的性能较差,但我们认为 AWS 选择使用基于 ToR 的网络而不是轨道优化设计的原因是 ToR 更便宜,并且可靠性更高,因为 ToR 架构可以使用从 AI 芯片到第一个直接交换机的铜线。相比之下,在轨道优化的情况下,每个 AI 芯片可能连接到远处的机架,因此需要在许多链路上使用光学器件。AWS 内部尝试过轨道优化,但由于上面讨论的可靠性影响以及出于快速部署的愿望,他们选择坚持使用 ToR 架构。减少光学器件的使用还可以减少因 AI 热潮带来的需求空前增长而导致的全球光学收发器持续短缺所造成的问题。
ToR 的另一个好处是,通常在 AI 集群中,横向扩展 NIC 到其第一个直接交换机只有一个单点故障。在 ToR 架构中,将横向扩展 NIC 连接到 ToR 交换机的无源 DAC 铜缆的 MTTF 提高了 100 倍,抖动减少了 100 倍。AWS 将在 NIC 和 ToR 交换机之间使用 400G QSFP-DD 到两个 200G QSFP56 无源铜缆。
对于机架内 ToR 交换机,我们认为大多数交换机将是基于 Marvell Teralynx 6.4T 和 12.8T 交换机芯片的白盒交换机。对于 ToR 交换机,AWS 在 Broadcom 和 Marvell 商用交换机 ASIC 之间进行多供应商采购。
对于 Leaf 和 Spine 交换机,AWS 将使用基于 Broadcom Tomahawk4 硅片的 1U 25.6T 白盒交换机。
AWS 不使用多个交换机来组成基于机箱的模块化交换机,因为这种设置的爆炸半径很大。如果机箱发生故障,则机箱连接的所有线卡和链路都会发生故障。这可能涉及数百个 Trainium2 芯片。由于潜在的爆炸半径很大,大多数超大规模企业通常对这些物理机箱模块化交换机不感兴趣。

相反,AWS 更喜欢使用虚拟模块化交换机,通过无源和有源铜缆将单个机架中的多个披萨盒 1U 交换机连接起来,形成一个模块化交换机。这样,就不会出现单一故障影响大范围的爆炸半径。
EBS+ENA+OOB
每个 Trainium2 物理服务器都将有一个专用的 80Gbit/s 链接,链接到称为“弹性块存储”(EBS)的 AWS 托管块存储,并有一个称为“弹性网络适配器”(ENA)的 100Gbit/s 前端链接。这些将提供对正常网络流量的快速访问,例如容器拉取、SLURM/Kubernetes 管理流量。这两个网络都使用 AWS 的内部 Nitro DPU 卡,可将 VPC 和安全功能卸载到硬件上,从而释放 CPU 资源。最重要的是,这些 Nitro 卡可以准确测量通过 NIC 的流量,从而准确地为该流量计费!请注意,物理张量和 AI 流量不会在这些网络上运行,而只会在我们之前讨论过的 EFAv3 横向扩展和 NeuronLinkv3 纵向扩展网络上运行。
网络连接器和电缆成本
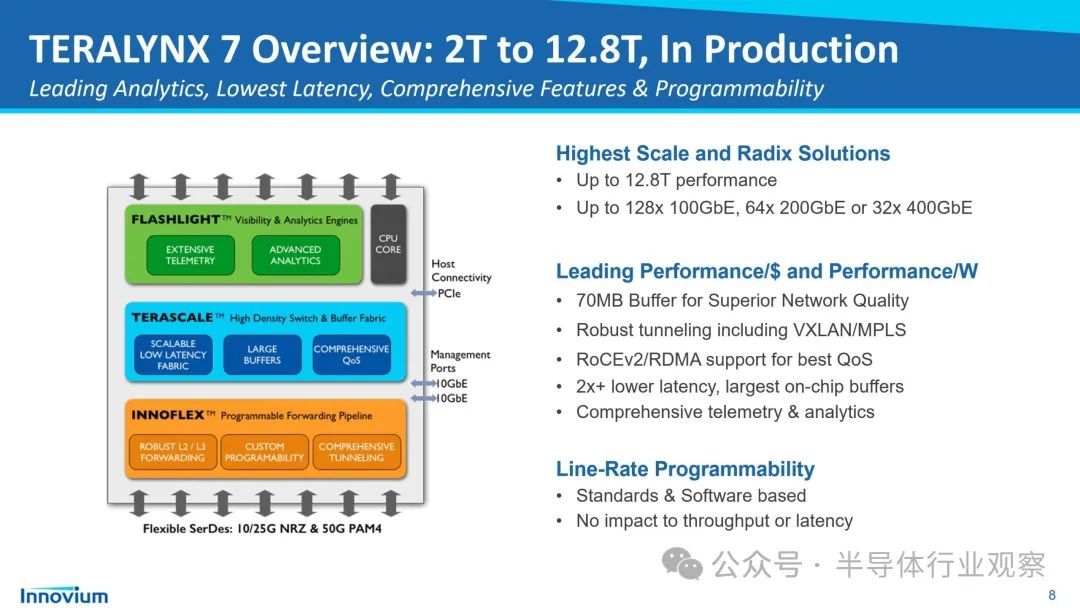
对于 Trainium2 的两个 SKU,TE 将是背板的唯一供应商,每台服务器将包括 48 个连接器和 1,536 条铜缆。与 GB200 NVL72 中 NVLink 电缆从 GPU 连接到 NVLink 交换机不同,对于 Trainium2,电缆是每个芯片之间的点对点。Trn2-Ultra SKU 还将配备 AEC 电缆,Astera Labs 将提供这些电缆。我们认为,每块芯片的网络连接器和电缆总成本将达到近 1,000 美元。
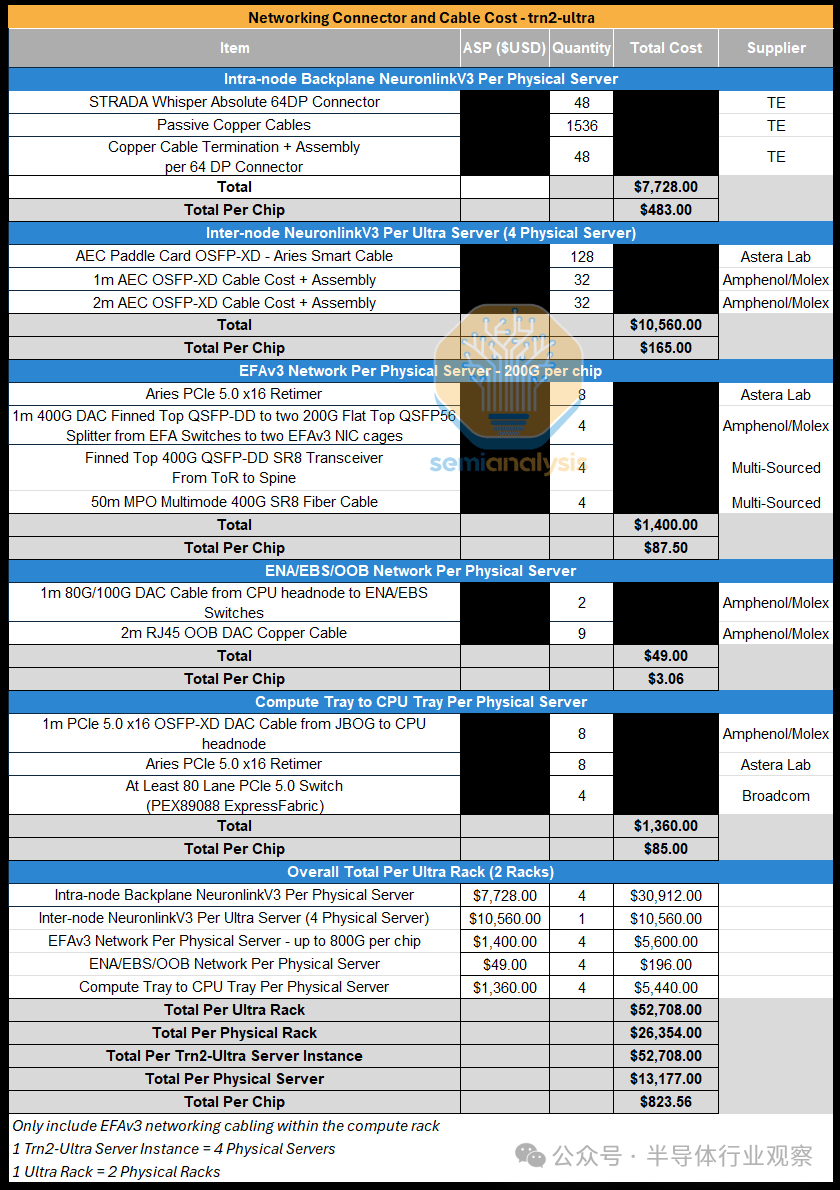
对于 Trn2 SKU,虽然没有服务器间的 NeuronLinkv3 AEC 电缆,但 EFAv3 带宽增加到每芯片 800Gbit/s 将超过这一节省,从而将网络连接器和电缆的总成本增加到每芯片约 1.2 万美元。
软件
设计定制 AI 芯片最具挑战性的方面之一是软件,其中 ML 编译器和集成到现有 ML 科学家工作流程中的强大用户体验都至关重要。
以前,在 Trainium 上,使用 AI 芯片的唯一途径是通过 Pytorch XLA Lazy Tensor ML 编译器,这是一个非常糟糕的 API,会导致大量错误,并且缺乏可移植性。我们认为 AWS Trainium 团队已经通过提供使用类似 Triton 的tile编程语言编写内核的直接访问权限进行了纠正。
此外,Trainium 软件团队现在为 JAX 提供了测试版支持,JAX 是一个更面向 XLA ML 编译器和环形拓扑静态编译 AI 芯片的 ML 框架。Trainium 和 Trainium2 与 TPU 非常相似,因为它们都是具有环形拓扑的巨型收缩阵列芯片,因此 Trainium 软件现在通过 XLA 支持 JAX 将是一个更合适的软件堆栈。
XLA
Pytorch XLA 的梦想是使用惰性张量来跟踪编译计算图和所有 Pytorch 操作,仅在遇到需要具体化的图部分时才在 Trainium 设备上运行图。这对于简单模型很有效,但惰性张量的问题在于,只要向 ML 模型架构添加任何类型的复杂性,就会出现大量错误。使用大量控制流语句会破坏惰性张量,尤其是在大量使用数据依赖控制流语句的情况下。此外,对于具有数十万个计算操作的巨型计算图(例如大型 LLM 模型),由于 Python 的速度通常较慢,惰性跟踪图也会导致高开销。
Pytorch XLA 的目标是,一旦 Pytorch<>XLA 将计算图跟踪到 StableHLO,XLA 便能够执行图优化,例如删除形成标识的子图并进行垂直 + 水平融合。然后,XLA 会将其降低为依赖于硬件的图,以进行矢量化和流水线优化,从而实现高性能内核。
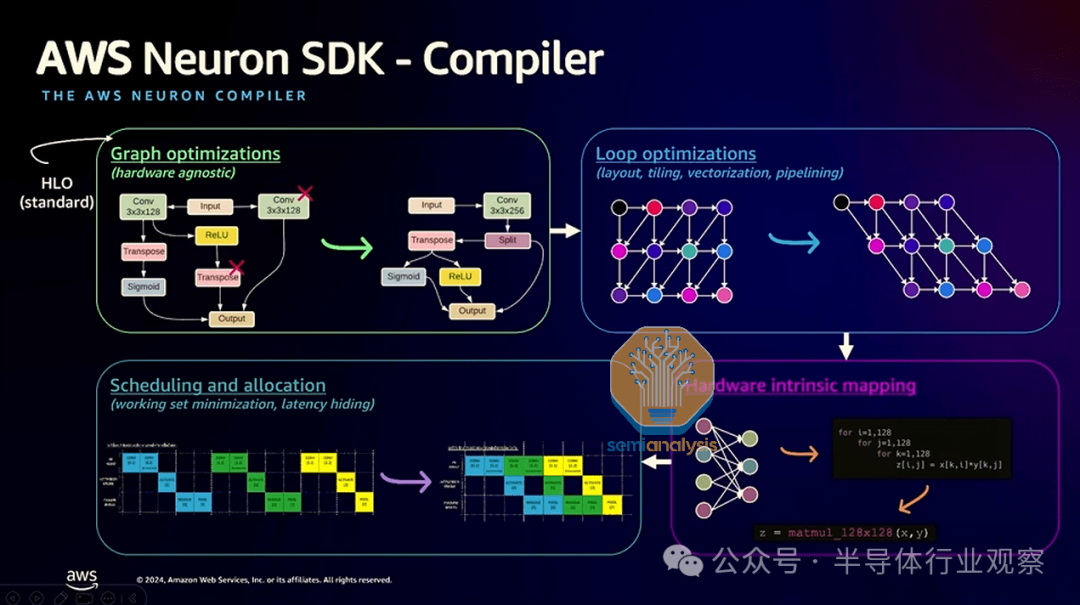
Pytorch 2.0 引入了一种使用称为“TorchDynamo”的 Python 字节码解释捕获计算图的新方法。
TorchDynamo 能够将计算图捕获到称为“Aten IR”的 IR 中,其中计算 IR 中的每个节点都是一个 Aten 操作。然后,编译器后端可以将此 Aten IR 图作为输入,并将其降低到特定于域的内部 IR,例如 XLA 的 StableHLO 或电感器 IR。我们相信这个 API 更适合 Trainium XLA,并且通过 Dyanmo API 对 Pytorch 的支持会更好。
关于 TorchDyanmo XLA 的不幸消息是,目前,TorchDynamo 将训练图分解为三个图(前向、后向、优化器步骤),而不是一个完整的图,这导致与 LazyTensor XLA 相比性能不佳。好消息是,Meta 团队正在努力在 TorchDynamo 中捕获完整图,这项工作将扩展到 TorchDynamo XLA。
对于 Trainium 来说,坏消息是,Pytorch<>XLA 代码路径通常未被 Meta 内部广泛使用,因此主要由 AWS 和 Google Pytorch 团队维护,这是 Pytorch<>XLA 代码路径存在大量错误的主要原因。此外,与 Jax 团队相比,Google 和 AWS Pytorch 团队都是二流团队,因为 Deepmind 和 Anthropic 等实验室的工作负载通过 Jax 堆栈运行。
同样,Meta 不会对 Pytorch AMD 代码路径进行广泛的内部现场测试。我们将在即将发表的文章“MI300X 与 H100 与 H200 的训练比较”中更多地讨论 AMD 的性能。AWS 团队应该与 Meta 合作,对 Trainium2 进行内部现场测试,以适应 Meta 的内部生产训练工作负载,让 Pytorch Trainium2 软件体验更加出色!
传统上,在使用 Google 的内部 XLA ML 编译器时,JAX 仅适用于 Google 的 TPU 芯片,但我们认为 JAX 的编程模型也非常适合 Trainium2,因为 TPU 和 Trainium2 都是具有巨型脉动阵列和使用 3D 圆环的静态编译图的 AI 芯片。这意味着 Trainium 可以直观地连接到 XLA Compiler 插件和 PRJT 运行时。JAX 的逻辑长方体网格和轴非常适合 Trainium 拓扑。AWS 最近宣布了其 JAX <> Trainium 集成的公开测试版,这是一个非常令人兴奋的方向。
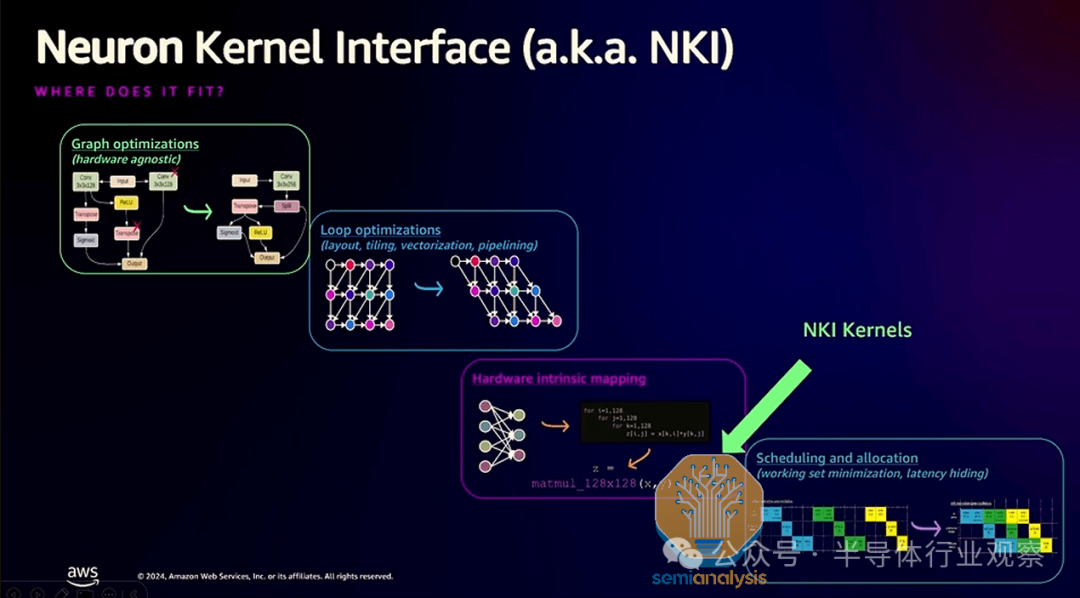
NKI 内核语言
神经元内核语言 (NKI:The Neuron Kernel Language) - 发音为“Nicky” - 是 Trainium 领域专用语言,用于编写类似于 NVIDIA 的 CUDA 和 OpenAI 的 Triton 语言的内核。与 Nvidia 的 CUDA 语言不同,NKI 基于类似于 OpenAI 的 Triton 编程语言的分块编程。NKI 将使专业程序员能够在 Trainium2 芯片上实现接近光速 (SOL) 的性能。
除了 AWS 自己的公共文档和内核示例外,为了传播 NKI 内核语言的知识和教育,亚马逊还与斯坦福大学合作,为学生布置作业,重点是编写现实世界的内核,例如融合卷积 + max_pool。我们喜欢他们前进的方向,因为为了与 CUDA 生态系统竞争,AWS 必须采取生态系统和开源方法围绕 NKI 内核语言进行教育。
分布式调试和分析工具
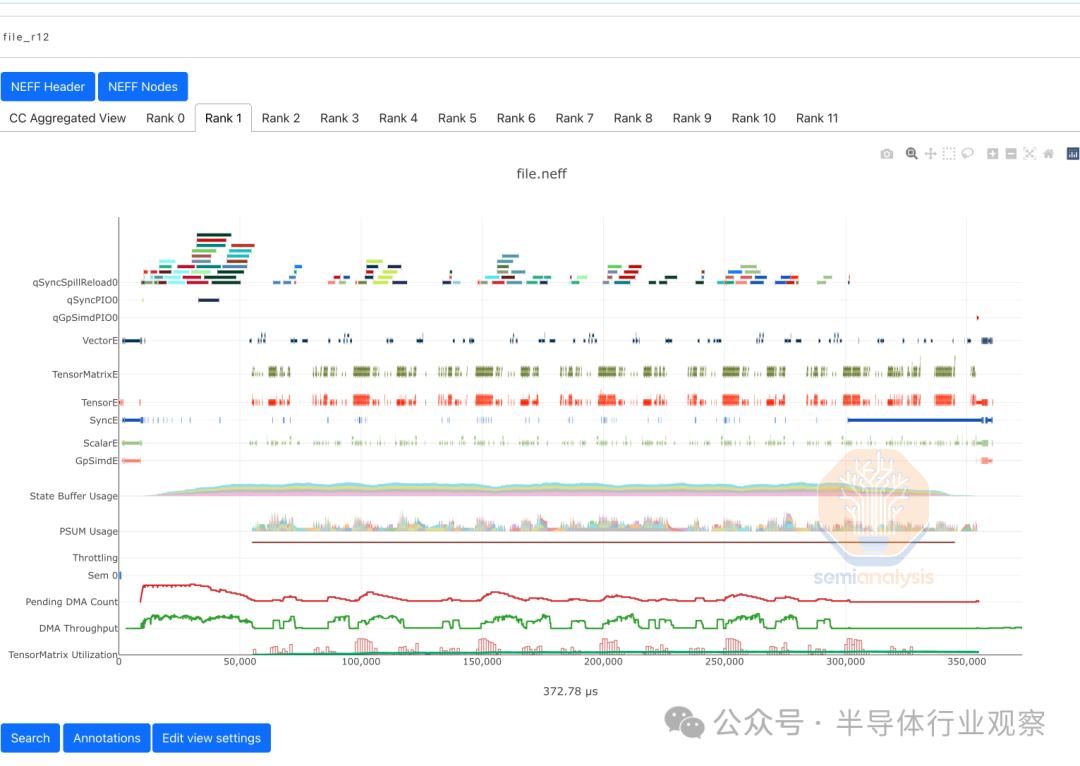
亚马逊还提供了非常细粒度的内核级和分布式系统级调试和分析工具,类似于 Nvidia 在其 GPU 生态系统上提供的工具。我们认为这是正确的方向,因为它使专家级最终用户能够注意到其训练和推理工作负载的瓶颈并加以解决。
与 Nvidia Nsight Compute 类似,您可以查看内核级别的分析并查看 Tensor Engine 的活动以及 SRAM 寄存器压力等。
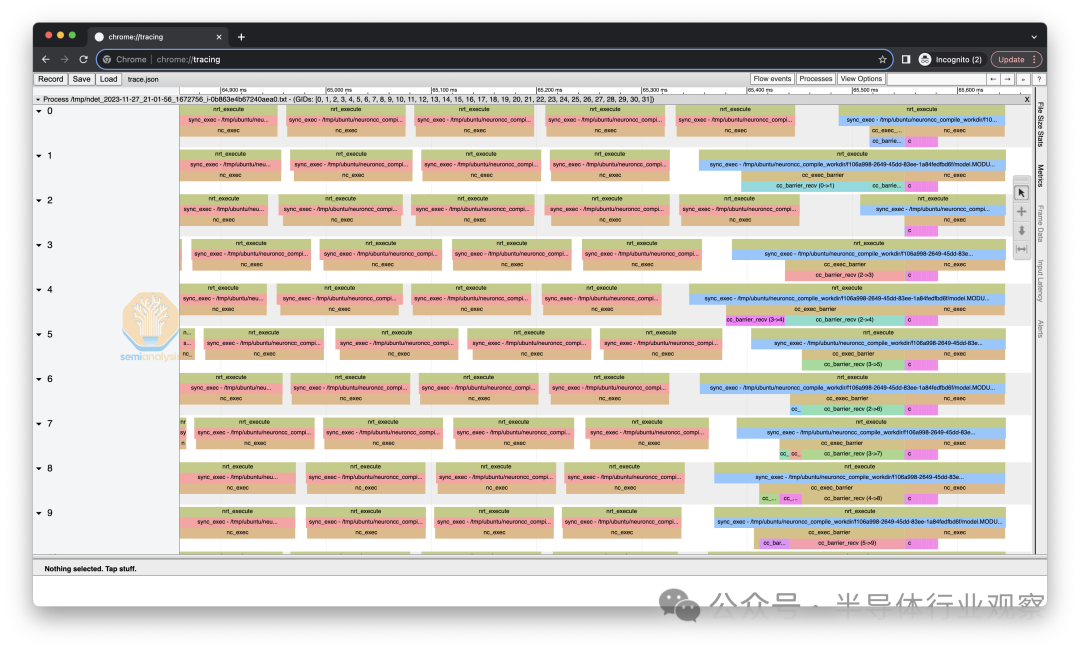
Nvidia 生态系统拥有 Nvidia Nsight Systems 和 Pytorch Perfetto 分析器等效工具,而 Trainium2 生态系统拥有 Neuron 分布式事件跟踪。这将允许 ML 工程师调试分布式性能问题,并查看通信与计算的重叠程度。在某些方面,这比开箱即用的 Pytorch 分析器更好,因为它会自动合并所有等级的所有跟踪,而不是让最终用户手动编写脚本来合并可能包含错误的等级。
此外,亚马逊还公布了大部分 ISA 和精确的周期时间,这使得开发人员在调试和分析时获得比在基于 Nvidia 的 GPU 上开发更积极的体验。这意味着从硬件中提取真正的光速要比 Nvidia GPU 容易得多,因为 Nvidia GPU 会故意向用户隐藏细节。
集体交流库(Collective Communication Library)
对于集体通信,AWS 创建了一个 Trainium 专用库,称为NeuronX Collective Communication Library。该库类似于 Nvidia 的 NCCL,因为它提供了一组集体通信算法和集体,例如 All Reduce、All Gather、Reduce Scatter 等,它们是专为 Trainium2 2D/3D 环面拓扑构建的。最终用户可以直接通过 C++ 接口(或通过 Python 绑定)访问此库,XLA ML 编译器也可以在复杂化阶段自动插入集体调用。Trainium2 还可以使用一种名为“GPUDirect RDMA”的技术直接与其 EFAv3 NIC 通信,而无需通过 CPU。此外,借助 AWS 的内部 libfabric,他们能够绕过内核操作系统,从而进一步减少数据包延迟。
Trainium NeuronX 集体通信库目前不支持 All to All 集体。All to All 集体对于混合专家 (MoE) 模型中使用的专家并行性极为重要。此问题于 2022 年 10 月打开,自大约 3 周前以来一直处于非活动状态,因为 AWS 希望支持DataBrick 的 DBRX MoE 模型和其他即将推出的模型。Databricks 最近宣布与 AWS 建立“合作伙伴关系”,使用 Trainium2 芯片进行训练和推理。我们相信 Databricks 将成为 GenAI 推理的第二大外部 Trainium2 客户。
超级服务器对之间的异步检查点
为了加快检查点速度,Trainium NeuronX 软件包提供了对跨主机检查点冗余的支持。Trainium2 芯片不会在检查点相对较慢的 S3 或 AWS Managed Lustre 存储时处于闲置状态,而是会快速检查点到自己服务器的 CPU RAM 和/或本地 NVMe 存储,之后 Trainium2 芯片将继续处理其工作负载。
这种方法的问题在于,如果服务器硬崩溃,则没有检查点的冗余或其他备份,从而导致许多 Trainium 小时的计算时间损失。
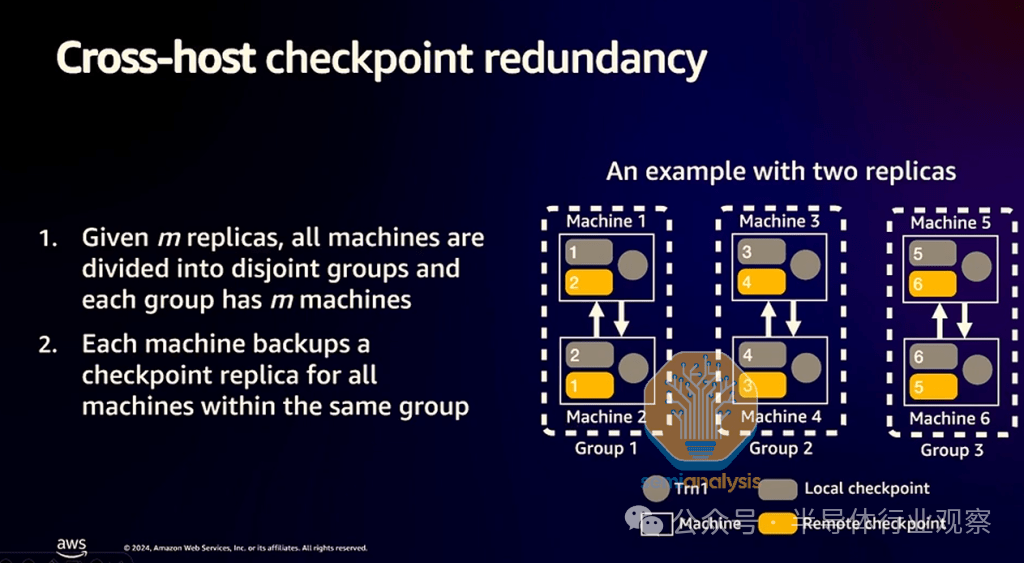
为了解决这个问题,Trainium2 服务器将能够以成对的方式缓慢地将检查点复制到其他服务器。此外,为了避免 Trainium2 服务器将其检查点复制到相邻服务器时导致训练速度减慢,AWS 声称能够在没有来自训练工作负载的通信时安排检查点复制流量。
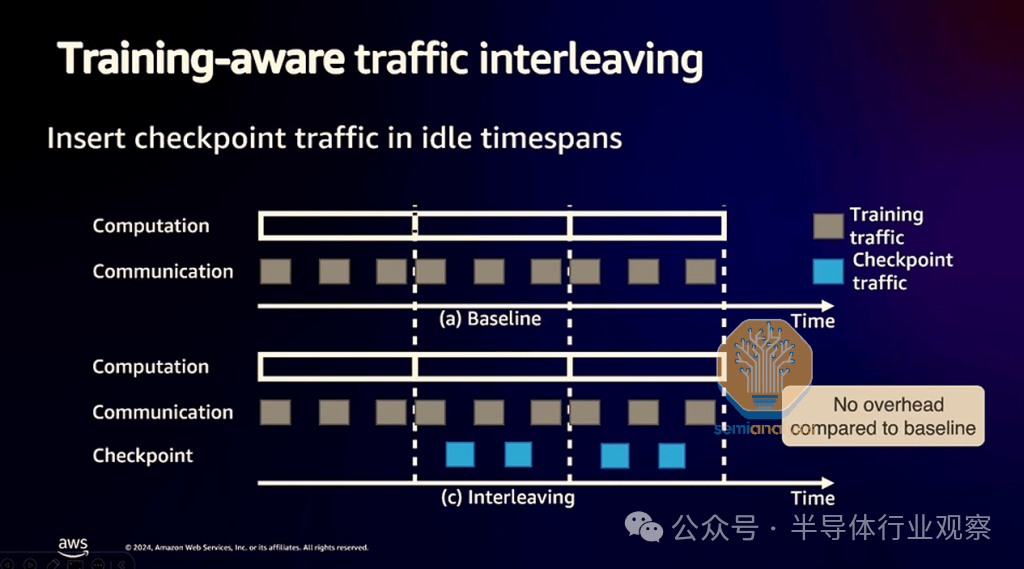
工作负载编排
Trainium2 的最终用户将采用类似 SLURM 的方法或类似 Kubernetes 的方法来协调他们的工作负载。
就类似 SLURM 的方法而言,AWS 提供两种托管服务,AWS ParallelCluster 和 AWS Batch。AWS ParallelCluster 基本上只是托管的 SLURM。SLURM 只是一个近似 Linux/bash 原语的编排器。许多来自学术实验室环境的 ML 工程师/科学家都非常喜欢 SLURM,因为它使用 bash 和 Linux 原语。在运行交互式作业和进行代码开发时,这是一种令人惊叹的体验。这与 Kubernetes 容器方法形成了鲜明对比,后者并不真正支持开箱即用的交互式作业。
在类似托管 Kubernetes 的工作负载编排方法方面,AWS 提供弹性 Kubernetes 服务 (EKS) 和弹性容器服务 (ECS)。Kubernetes 并非为批处理作业(例如需要成组调度的训练工作负载)而构建的现成服务。Kubernetes 非常适合面向服务的工作负载(例如推理),其中每个副本大多数时候只是一台服务器,因此可以只是一个 Kubernetes pod。
让 Kubernetes 适用于训练的批处理/群组调度需要大量工作,让 Kubernetes 适用于交互式工作负载也需要大量工作。因此,我们实际上只看到 OpenAI 和字节跳动等最大的 AI 实验室采用这种方法,因为它们有能力让内部集群工程师构建工具来让 Kubernetes 适用于群组训练和交互式工作负载。
最后,Kubernetes 通常更适合用于代理训练/推理以及为 AI 代理启动和关闭容器。我们希望这些容器能够得到强化,以防止 AGI 泄漏。
自动被动和主动健康检查
当在单个工作负载中扩展到数万个 AI 芯片时,可靠性是确保训练工作负载成功完成的重要方面。这就是 Nvidia 发布 DCGM 工具的原因。借助 DCGM 诊断,最终用户可以通过数字和全芯片自检检测集群中发生的 80% 的静默数据损坏 (SDC)。我们看到的另一个有趣且相关的功能是Neocloud 巨头Nebius ,它在其操作员工作负载调度程序中实现了一项功能,他们可以通过 CRON 作业安排主动健康检查。
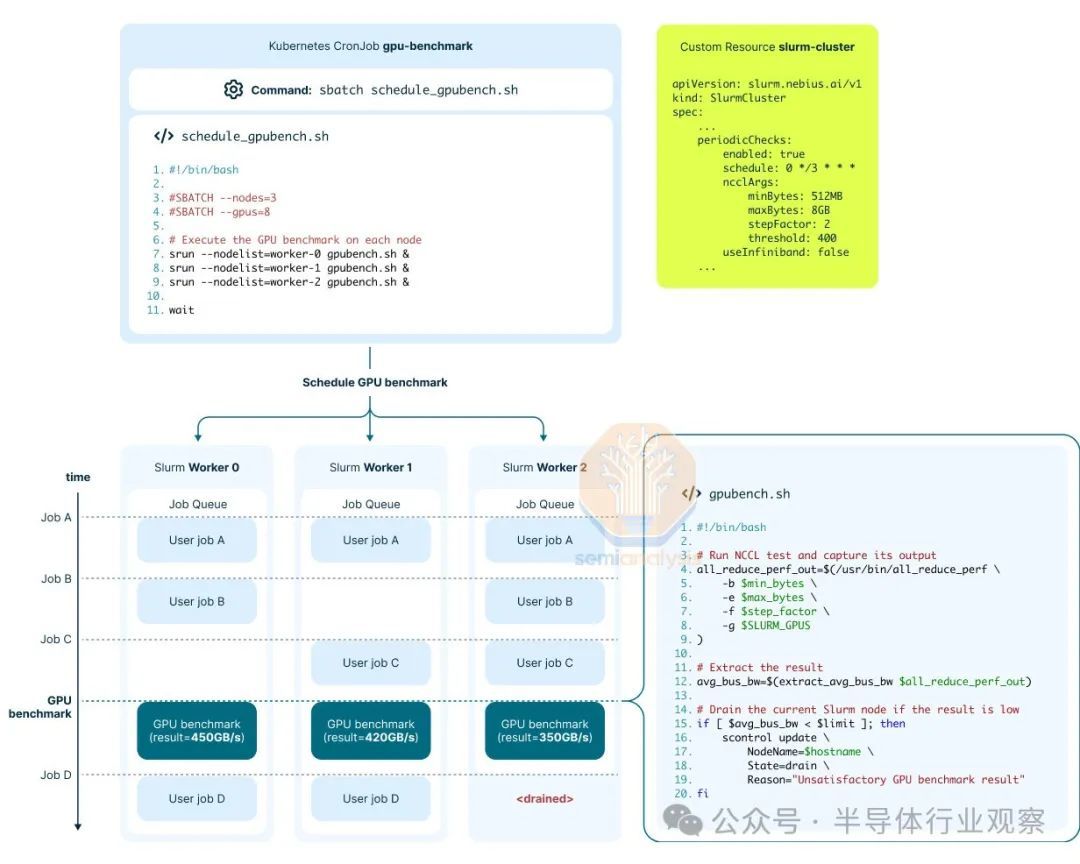
这些主动健康检查可以检查 Nvidia GPU 的 NVLink 网络并运行一系列其他检查。此外,他们能够通过禁用 NVLink 仅使用一个节点自行测试其 InfiniBand 结构,而不是像其他用户在测试使用多个节点的 IB 时所做的那样。
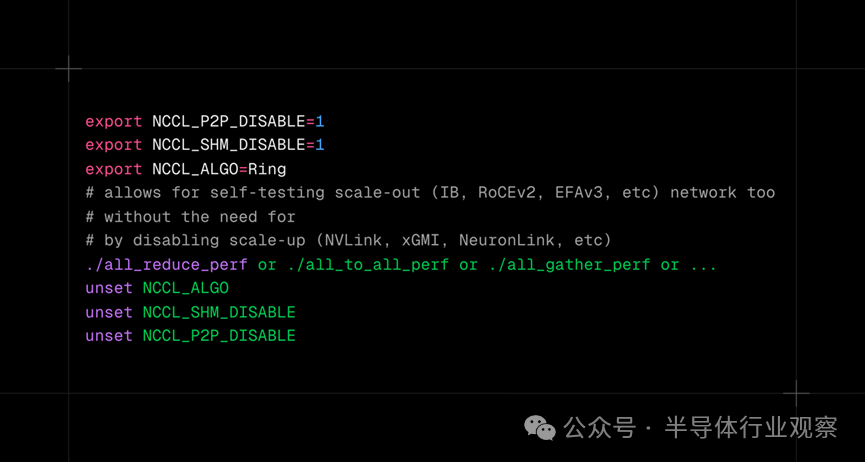
对于 Trainium2 软件堆栈,也有类似的工具。可以使用 NCCOM 本地测试来自我测试 NeuronLink 和/或横向扩展 EFAv3 链接。此外,AWS 还提供了一个测试,该测试运行一个小型训练工作负载并确保该工作负载的实际输出与黄金工作负载相匹配。
参考链接
https://semianalysis.com/2024/12/03/amazons-ai-self-sufficiency-trainium2-architecture-networking/十倍杠杆炒股